What to monitor
Monitor the directory service for the following reasons:
-
Noticing availability problems as they occur.
If a server becomes unresponsive, goes offline, or crashes, you discover the problem quickly, and take corrective action.
-
Identifying how client applications use the directory service.
You can parse directory access logs to determine what client applications do. This information helps you understand what is most important, and make decisions about indexing, for example.
Access log messages can also provide evidence of security threats, and traces of insecure client application behavior.
-
Spotting performance problems, where the directory service does not meet habitual, expected, or formally defined functional, throughput, or response time characteristics.
For example, if it suddenly becomes impossible to perform updates, the directory service has a performance problem. Alternatively, if a search that regularly completes in 500 milliseconds now takes 15 seconds, the directory service has a performance problem.
A performance problem could also be evidence of a security threat.
Monitoring directory security is thus part of an overall monitoring strategy. Aim to answer at least the following questions when monitoring specifically for security problems:
-
What insecure client behaviors do you observe?
Examples:
-
Attempts to send simple bind credentials over insecure connections
-
Attempts to change passwords over insecure connections
-
Attempts to change configuration over insecure connections
-
-
What unusual or unexpected usage patterns do you observe?
Examples:
-
Search requests that perform unindexed searches
-
Requests that hit resource limits
-
Unusually large numbers of bind requests that fail
-
Unusual large numbers of password change requests that fail
-
Unusual large numbers of account lockout events
-
-
Are you observing any sudden or hard-to-explain performance problems?
Examples:
-
Unusual increases in throughput
-
Unusual increases in response times for typical requests
-
Servers suddenly starved for system resources
-
Keep in mind when you notice evidence of what looks like a security problem that it might be explained by a mistake made by an administrator or an application developer. Whether the problem is due to malice or user error, you can nevertheless use monitoring information to guide corrective actions.
HTTP-based monitoring
|
This page covers the HTTP interfaces for monitoring DS servers. For the same capabilities over LDAP, refer to LDAP-based monitoring. |
DS servers publish monitoring information at these HTTP endpoints:
/alive-
Whether the server is currently alive, meaning its internal checks have not found any errors that would require administrative action.
/healthy-
Whether the server is currently healthy, meaning it is alive, the replication server is accepting connections on the configured port, and any replication delays are below the configured threshold.
/metrics/prometheus-
Monitoring information in Prometheus monitoring software format. For details, refer to Prometheus metrics reference.
The following example command accesses the Prometheus endpoint:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheusbash
To give a regular user privileges to read monitoring data, refer to Monitor privilege.
Basic availability
Server is alive (HTTP)
The following example reads the /alive endpoint anonymously.
If the DS server’s internal tests do not find errors that require administrative action,
then it returns HTTP 200 OK:
$ curl --cacert ca-cert.pem --head https://localhost:8443/alive
HTTP/1.1 200 OK
...If the server finds that it is subject to errors requiring administrative action, it returns HTTP 503 Service Unavailable.
If there are errors, anonymous users receive only the 503 error status.
Error strings for diagnosis are returned as an array of "alive-errors" in the response body,
but the response body is only returned to a user with the monitor-read privilege.
When a server returns "alive-errors", diagnose and fix the problem, and then either restart or replace the server.
Server health (HTTP)
The following example reads the /healthy endpoint anonymously.
If the DS server is alive, as described in Server is alive (HTTP),
any replication listener threads are functioning normally,
and any replication delay is below the threshold configured as
max-replication-delay-health-check
(default: 5 seconds), then it returns HTTP 200 OK:
$ curl --cacert ca-cert.pem --head https://localhost:8443/healthy
HTTP/1.1 200 OK
...If the server is subject to a replication delay above the threshold, then it returns HTTP 503 Service Unavailable. This result only indicates a problem if the replication delay is steadily high and increasing for the long term.
If there are errors, anonymous users receive only the 503 error status.
Error strings for diagnosis are returned as an array of "ready-errors" in the response body,
but the response body is only returned to a user with the monitor-read privilege.
When a server returns "ready-errors", route traffic to another server until the current server is ready again.
Server health (Prometheus)
In addition to the examples above, you can monitor whether a server is alive and able to handle requests as Prometheus metrics:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep health_status
# HELP ds_health_status_alive Indicates whether the server is alive
# TYPE ds_health_status_alive gauge
ds_health_status_alive 1.0
# HELP ds_health_status_healthy Indicates whether the server is able to handle requests
# TYPE ds_health_status_healthy gauge
ds_health_status_healthy 1.0Disk space (Prometheus)
The following example shows monitoring metrics you can use to check whether the server is running out of disk space:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep disk
# HELP ds_disk_free_space_bytes The amount of free disk space (in bytes)
# TYPE ds_disk_free_space_bytes gauge
ds_disk_free_space_bytes{disk="<partition>",} <bytes>
# HELP ds_disk_free_space_full_threshold_bytes The effective full disk space threshold (in bytes)
# TYPE ds_disk_free_space_full_threshold_bytes gauge
ds_disk_free_space_full_threshold_bytes{disk="<partition>",} <bytes>
# HELP ds_disk_free_space_low_threshold_bytes The effective low disk space threshold (in bytes)
# TYPE ds_disk_free_space_low_threshold_bytes gauge
ds_disk_free_space_low_threshold_bytes{disk="<partition>",} <bytes>In your monitoring software, compare free space with the disk low and disk full thresholds. For database backends, these thresholds are set using the configuration properties: disk-low-threshold and disk-full-threshold.
When you read from cn=monitor instead ,as described in LDAP-based monitoring,
the relevant data are exposed on child entries of cn=disk space monitor,cn=monitor.
Certificate expiration (Prometheus)
The following example shows how you can use monitoring metrics to check whether the server certificate is due to expire soon:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep cert
# HELP ds_certificates_certificate_expires_at_seconds Certificate expiration date and time
# TYPE ds_certificates_certificate_expires_at_seconds gauge
ds_certificates_certificate_expires_at_seconds{alias="ssl-key-pair",key_manager="PKCS12",} <sec_since_epoch>In your monitoring software, compare the expiration date with the current date.
When you read from cn=monitor instead, as described in LDAP-based monitoring,
the relevant data are exposed on child entries of cn=certificates,cn=monitor.
Activity
Active users (Prometheus)
DS server connection handlers respond to client requests. The following example uses the default monitor user account to read active connections on each connection handler:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep "active_[cp]"Request statistics (Prometheus)
DS server connection handlers respond to client requests. The following example uses the default monitor user account to read statistics about client operations on each of the available connection handlers:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep connection_handlersWork queue (Prometheus)
DS servers have a work queue to track request processing by worker threads, and whether the server has rejected any requests due to a full queue. If enough worker threads are available, then no requests are rejected. The following example uses the default monitor user account to read statistics about the work queue:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep work_queueTo adjust the number of worker threads, refer to the settings for Traditional Work Queue.
Counts
ACIs (Prometheus)
DS maintains counts of ACIs:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep _aciDatabase size (Prometheus)
DS servers maintain counts of the number of entries in each backend. The following example uses the default monitor user account to read the counts:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep backend_entry_countEntry caches (Prometheus)
DS servers maintain entry cache statistics:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep entry_cacheGroups (Prometheus)
The following example reads counts of static, dynamic, and virtual static groups, and statistics on the distribution of static group size:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep -i groupAt startup time, DS servers log a message showing the number of different types of groups and the memory allocated to cache static groups.
Subentries (Prometheus)
DS maintains counts of LDAP subentries:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep subentriesIndexing
Index cost (Prometheus)
DS maintains metrics about index cost. The metrics count the number of updates and how long they took since the DS server started.
The following example demonstrates how to read the metrics for all monitored indexes:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep index_costIndex use (Prometheus)
DS maintains metrics about index use. The metrics indicate how often an index was accessed since the DS server started.
The following example demonstrates how to read the metrics for all monitored indexes:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep index_usesReplication
Monitor the following to ensure replication runs smoothly. Take action as described in these sections and in the troubleshooting documentation for replication problems.
Replication delay (Prometheus)
The following example reads a metric to check the delay in replication:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep receive_delay
# HELP ds_replication_replica_remote_replicas_receive_delay_seconds Current local delay in receiving replicated operations
# TYPE ds_replication_replica_remote_replicas_receive_delay_seconds gauge
ds_replication_replica_remote_replicas_receive_delay_seconds{<labels>} <delay>DS replicas measure replication delay as the local delay when receiving and replaying changes. A replica calculates these local delays based on changes received from other replicas. Therefore, a replica can only calculate delays based on changes it has received. Network outages cause inaccuracy in delay metrics.
A replica calculates delay metrics based on times reflecting the following events:
-
t0: the remote replica records the change in its data
-
t1: the remote replica sends the change to a replica server
-
t2: the local replica receives the change from a replica server
-
t3: the local replica applies the change to its data
This figure illustrates when these events occur:

Replication keeps track of changes using change sequence numbers (CSNs), opaque and unique identifiers for each change that indicate when and where each change first occurred. The tn values are CSNs.
When the CSNs for the last change received and the last change replayed are identical, the replica has applied all the changes it has received. In this case, there is no known delay. The receive and replay delay metrics are set to 0 (zero).
When the last received and last replayed CSNs differ:
-
Receive delay is set to the time t2 - t0 for the last change received.
Another name for receive delay is current delay.
-
Replay delay is approximately t3 - t2 for the last change replayed. In other words, it is an approximation of how long it took the last change to be replayed.
As long as replication delay tends toward zero regularly and over the long term, temporary spikes and increases in delay measurements are normal. When all replicas remain connected and yet replication delay remains high and increases over the long term, the high replication delay indicates a problem. Steadily high and increasing replication delay shows that replication is not converging, and the service is failing to achieve eventual consistency.
For a current snapshot of replication delays, you can also use the dsrepl status command.
For details, refer to Replication status.
Replication status (Prometheus)
The following example checks the replication status metrics:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep replica_statusThe effective replica status is the gauge whose value is 1.0.
For example, this output shows normal status:
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="BAD_DATA",} 0.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="DEGRADED",} 0.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="FULL_UPDATE",} 0.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="INVALID",} 0.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="NORMAL",} 1.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="NOT_CONNECTED",} 0.0
ds_replication_replica_status{domain_name="dc=example,dc=com",server_id="evaluation-only",status="TOO_LATE",} 0.0
The DEGRADED status is for backwards compatibility only.
|
If the status is not Normal, how you react depends on the value of
the ds-mon-status attribute for LDAP, or ds_replication_replica_status{status} for Prometheus:
| Status | Explanation | Actions to Take |
|---|---|---|
|
Replication is broken. Internally, DS replicas store a shorthand form of the initial state called a generation ID. The generation ID is a hash of the first 1000 entries in a backend. If the replicas' generation IDs match, the servers can replicate data without user intervention. If the replicas' generation IDs do not match for a given backend, you must manually initialize replication between them to force the same initial state on all replicas. This status arises for one of the following reasons:
DS 7.3 introduced this status.
Earlier releases included this state as part of the |
Whenever this status displays:
|
|
Replication is operating normally. You have chosen to initialize replication over the network. The time to complete the operation depends on the network bandwidth and volume of data to synchronize. |
Monitor the server output and wait for initialization to complete. |
|
This status arises for one of the following reasons:
|
If this status happens during normal operation:
|
|
Replication is operating normally. |
Nothing to do. |
|
This status arises for one of the following reasons:
|
If this status happens during normal operation:
|
|
The replica has fallen further behind the replication server than allowed by the replication-purge-delay. In other words, the replica is missing too many changes, and lacks the historical information required to synchronize with peer replicas. The replica no longer receives updates from replication servers. Other replicas that recognize this status stop returning referrals to this replica. DS 7.3 introduced this status.
Earlier releases included this state as part of the |
Whenever this status displays:
|
Change number indexing (Prometheus)
DS replication servers maintain a changelog database to record updates to directory data. The changelog database serves to:
-
Replicate changes, synchronizing data between replicas.
-
Let client applications get change notifications.
DS replication servers purge historical changelog data after the replication-purge-delay
in the same way replicas purge their historical data.
Client applications can get changelog notifications using cookies (recommended) or change numbers.
To support change numbers, the servers maintain a change number index to the replicated changes.
A replication server maintains the index when its configuration properties include
changelog-enabled:enabled.
(Cookie-based notifications do not require a change number index.)
The change number indexer must not be interrupted for long. Interruptions can arise when, for example, a DS server:
-
Stays out of contact, not sending any updates or heartbeats.
-
Gets removed without being shut down cleanly.
-
Gets lost in a system crash.
Interruptions prevent the change number indexer from advancing. When a change number indexer cannot advance for almost as long as the purge delay, it may be unable to recover as the servers purge historical data needed to determine globally consistent change numbers.
The following example checks the state of change number indexing:
$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep change_number_
# HELP ds_change_number_indexing_state Automatically generated
# TYPE ds_change_number_indexing_state gauge
ds_change_number_indexing_state{indexing_state="BLOCKED_BY_REPLICA_NOT_IN_TOPOLOGY",} 0.0
ds_change_number_indexing_state{indexing_state="INDEXING",} 1.0
ds_change_number_indexing_state{indexing_state="WAITING_ON_UPDATE_FROM_REPLICA",} 0.0
# HELP ds_change_number_time_since_last_indexing_seconds Duration since the last time a change was indexed
# TYPE ds_change_number_time_since_last_indexing_seconds gauge
ds_change_number_time_since_last_indexing_seconds 0.0
# HELP ds_replication_changelog_purge_waiting_for_change_number_indexing Indicates whether changelog purging is waiting for change number indexing to advance. If true, check the ds-mon-indexing-state and ds-mon-replicas-preventing-indexing metrics
# TYPE ds_replication_changelog_purge_waiting_for_change_number_indexing gauge
ds_replication_changelog_purge_waiting_for_change_number_indexing 0.0When ds_change_number_indexing_state has
BLOCKED_BY_REPLICA_NOT_IN_TOPOLOGY or WAITING_ON_UPDATE_FROM_REPLICA greater than 0,
refer to ds_change_number_time_since_last_indexing_seconds for the wait time in seconds
and to the
LDAP ds-mon-replicas-preventing-indexing metric for the list of problem servers.
Filtering results (Prometheus)
By default, DS servers return all Prometheus metrics.
To limit what the server returns, set one of these HTTP endpoint properties for the /metrics/prometheus:
Set these properties to valid Java regular expression patterns.
The following configuration change causes the server to return only ds_connection_handlers_ldap_requests_* metrics.
As mentioned in the reference documentation, "The metric name prefix must not be included in the filter."
Notice that the example uses connection_handlers_ldap_requests, not including the leading ds_:
$ dsconfig \
set-http-endpoint-prop \
--endpoint-name /metrics/prometheus \
--set included-metric-pattern:'connection_handlers_ldap_requests' \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptThe following configuration change causes the server to exclude metrics whose names start with ds_jvm_.
Notice that the example uses the regular expression jvm_.*:
$ dsconfig \
set-http-endpoint-prop \
--endpoint-name /metrics/prometheus \
--set excluded-metric-pattern:'jvm_.*' \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptLDAP-based monitoring
|
This page covers the LDAP interfaces for monitoring DS servers. For the same capabilities over HTTP, refer to HTTP-based monitoring. |
DS servers publish whether the server is alive and able to handle requests in the root DSE.
They publish monitoring information over LDAP under the entry cn=monitor.
The following example reads all available monitoring entries:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(&)"The monitoring entries under cn=monitor reflect activity since the server started.
Many types of metrics are exposed. For details, refer to LDAP metrics reference.
Basic availability
Server health (LDAP)
Anonymous clients can monitor the health status of the DS server
by reading the alive attribute of the root DSE:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--baseDN "" \
--searchScope base \
"(&)" \
alive
dn:
alive: trueWhen alive is true, the server’s internal tests have not found any errors requiring administrative action.
When it is false, fix the errors and either restart or replace the server.
If the server returns false for this attribute, get error information,
as described in Server health details (LDAP).
Server health details (LDAP)
The default monitor user can check whether the server is alive
and able to handle requests on cn=health status,cn=monitor:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN "cn=health status,cn=monitor" \
--searchScope base \
"(&)"
dn: cn=health status,cn=monitor
ds-mon-alive: true
ds-mon-healthy: true
objectClass: top
objectClass: ds-monitor
objectClass: ds-monitor-health-status
cn: health statusWhen the server is either not alive or not able to handle requests,
this entry includes error diagnostics as strings on the ds-mon-alive-errors and ds-mon-healthy-errors attributes.
Activity
Active users (LDAP)
DS server connection handlers respond to client requests. The following example uses the default monitor user account to read the metrics about active connections on each connection handler:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-connection*)" \
ds-mon-active-connections-count ds-mon-active-persistent-searches ds-mon-connection ds-mon-listen-addressFor details about the content of metrics returned, refer to Metric types reference.
Request statistics (LDAP)
DS server connection handlers respond to client requests. The following example uses the default monitor user account to read statistics about client operations on each of the available connection handlers:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN "cn=connection handlers,cn=monitor" \
"(&)"For details about the content of metrics returned, refer to Metric types reference.
Work queue (LDAP)
DS servers have a work queue to track request processing by worker threads, and whether the server has rejected any requests due to a full queue. If enough worker threads are available, then no requests are rejected. The following example uses the default monitor user account to read statistics about the work queue:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN "cn=work queue,cn=monitor" \
"(&)"For details about the content of metrics returned, refer to Metric types reference. To adjust the number of worker threads, refer to the settings for Traditional Work Queue.
Counts
ACIs (LDAP)
DS maintains counts of ACIs:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-aci)" \
ds-mon-entries-acis-count ds-mon-entries-with-aci-attributes-count ds-mon-global-acis-countDatabase size (LDAP)
DS servers maintain counts of the number of entries in each backend and under each base DN. The following example uses the default monitor user account to read the counts:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(|(ds-mon-backend-entry-count=*)(ds-mon-base-dn-entry-count=*))" \
ds-mon-backend-entry-count ds-mon-base-dn-entry-countEntry caches (LDAP)
DS servers maintain entry cache statistics:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-entry-cache)" \Entry caches for groups have their own monitoring entries.
Groups (LDAP)
The following example reads counts of static, dynamic, and virtual static groups, and statistics on the distribution of static group size:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-groups)" \
ds-mon-dynamic-groups-count ds-mon-static-groups-count ds-mon-virtual-static-groups-count \
ds-mon-static-group-size-less-or-equal-to-100 \
ds-mon-static-group-size-less-or-equal-to-1000 \
ds-mon-static-group-size-less-or-equal-to-10000 \
ds-mon-static-group-size-less-or-equal-to-100000 \
ds-mon-static-group-size-less-or-equal-to-1000000 \
ds-mon-static-group-size-less-or-equal-to-infAt startup time, DS servers log a message showing the number of different types of groups and the memory allocated to cache static groups.
Subentries (LDAP)
DS maintains counts of LDAP subentries:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-subentries)" \
ds-mon-collective-attribute-subentries-count \
ds-mon-password-policy-subentries-countIndexing
Index use (LDAP)
DS maintains metrics about index use. The metrics indicate how often an index was accessed since the DS server started.
The following example demonstrates how to read the metrics for all monitored indexes:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-backend-index)" ds-mon-index ds-mon-index-usesIndex cost (LDAP)
DS maintains metrics about index cost. The metrics count the number of updates and how long they took since the DS server started.
The following example demonstrates how to read the metrics for all monitored indexes:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-backend-index)" ds-mon-index ds-mon-index-costLogging
DS maintains a list of supported logging categories. The following example reads the list:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-logging)"Replication
Monitor the following to ensure replication runs smoothly. Take action as described in these sections and in the troubleshooting documentation for replication problems.
Replication delay (LDAP)
The following example uses the default monitor user account to check the delay in replication:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(ds-mon-receive-delay=*)" \
ds-mon-receive-delay
dn: ds-mon-domain-name=cn=schema,cn=replicas,cn=replication,cn=monitor
ds-mon-receive-delay: <delay>
dn: ds-mon-domain-name=dc=example\,dc=com,cn=replicas,cn=replication,cn=monitor
ds-mon-receive-delay: <delay>
dn: ds-mon-domain-name=uid=monitor,cn=replicas,cn=replication,cn=monitor
ds-mon-receive-delay: <delay>DS replicas measure replication delay as the local delay when receiving and replaying changes. A replica calculates these local delays based on changes received from other replicas. Therefore, a replica can only calculate delays based on changes it has received. Network outages cause inaccuracy in delay metrics.
A replica calculates delay metrics based on times reflecting the following events:
-
t0: the remote replica records the change in its data
-
t1: the remote replica sends the change to a replica server
-
t2: the local replica receives the change from a replica server
-
t3: the local replica applies the change to its data
This figure illustrates when these events occur:
Replication keeps track of changes using change sequence numbers (CSNs), opaque and unique identifiers for each change that indicate when and where each change first occurred. The tn values are CSNs.
When the CSNs for the last change received and the last change replayed are identical, the replica has applied all the changes it has received. In this case, there is no known delay. The receive and replay delay metrics are set to 0 (zero).
When the last received and last replayed CSNs differ:
-
Receive delay is set to the time t2 - t0 for the last change received.
Another name for receive delay is current delay.
-
Replay delay is approximately t3 - t2 for the last change replayed. In other words, it is an approximation of how long it took the last change to be replayed.
As long as replication delay tends toward zero regularly and over the long term, temporary spikes and increases in delay measurements are normal. When all replicas remain connected and yet replication delay remains high and increases over the long term, the high replication delay indicates a problem. Steadily high and increasing replication delay shows that replication is not converging, and the service is failing to achieve eventual consistency.
For a current snapshot of replication delays, you can also use the dsrepl status command.
For details, refer to Replication status.
Replication status (LDAP)
The following example uses the default monitor user account to check the replication status of the local replica:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(ds-mon-status=*)" \
ds-mon-status
dn: ds-mon-domain-name=dc=example\,dc=com,cn=replicas,cn=replication,cn=monitor
ds-mon-status: NormalIf the status is not Normal, how you react depends on the value of
the ds-mon-status attribute for LDAP, or ds_replication_replica_status{status} for Prometheus:
| Status | Explanation | Actions to Take |
|---|---|---|
|
Replication is broken. Internally, DS replicas store a shorthand form of the initial state called a generation ID. The generation ID is a hash of the first 1000 entries in a backend. If the replicas' generation IDs match, the servers can replicate data without user intervention. If the replicas' generation IDs do not match for a given backend, you must manually initialize replication between them to force the same initial state on all replicas. This status arises for one of the following reasons:
DS 7.3 introduced this status.
Earlier releases included this state as part of the |
Whenever this status displays:
|
|
Replication is operating normally. You have chosen to initialize replication over the network. The time to complete the operation depends on the network bandwidth and volume of data to synchronize. |
Monitor the server output and wait for initialization to complete. |
|
This status arises for one of the following reasons:
|
If this status happens during normal operation:
|
|
Replication is operating normally. |
Nothing to do. |
|
This status arises for one of the following reasons:
|
If this status happens during normal operation:
|
|
The replica has fallen further behind the replication server than allowed by the replication-purge-delay. In other words, the replica is missing too many changes, and lacks the historical information required to synchronize with peer replicas. The replica no longer receives updates from replication servers. Other replicas that recognize this status stop returning referrals to this replica. DS 7.3 introduced this status.
Earlier releases included this state as part of the |
Whenever this status displays:
|
Change number indexing (LDAP)
DS replication servers maintain a changelog database to record updates to directory data. The changelog database serves to:
-
Replicate changes, synchronizing data between replicas.
-
Let client applications get change notifications.
DS replication servers purge historical changelog data after the replication-purge-delay
in the same way replicas purge their historical data.
Client applications can get changelog notifications using cookies (recommended) or change numbers.
To support change numbers, the servers maintain a change number index to the replicated changes.
A replication server maintains the index when its configuration properties include
changelog-enabled:enabled.
(Cookie-based notifications do not require a change number index.)
The change number indexer must not be interrupted for long. Interruptions can arise when, for example, a DS server:
-
Stays out of contact, not sending any updates or heartbeats.
-
Gets removed without being shut down cleanly.
-
Gets lost in a system crash.
Interruptions prevent the change number indexer from advancing. When a change number indexer cannot advance for almost as long as the purge delay, it may be unable to recover as the servers purge historical data needed to determine globally consistent change numbers.
The following example uses the default monitor user account to check the state of change number indexing:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN "cn=changelog,cn=replication,cn=monitor" \
"(objectClass=ds-monitor-change-number-indexing)" \
ds-mon-indexing-state ds-mon-time-since-last-indexing ds-mon-replicas-preventing-indexing
dn: cn=change number indexing,cn=changelog,cn=replication,cn=monitor
ds-mon-indexing-state: INDEXING
ds-mon-time-since-last-indexing: 0When ds-mon-indexing-state: BLOCKED_BY_REPLICA_NOT_IN_TOPOLOGY
or ds-mon-indexing-state: WAITING_ON_UPDATE_FROM_REPLICA,
refer to ds-mon-time-since-last-indexing for the wait time in milliseconds
and to ds-mon-replicas-preventing-indexing for the list of problem servers.
Monitor privilege
The following example assigns the required privilege to Kirsten Vaughan’s entry to read monitoring data, and shows monitoring information for the backend holding Example.com data:
$ ldapmodify \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password << EOF
dn: uid=kvaughan,ou=People,dc=example,dc=com
changetype: modify
add: ds-privilege-name
ds-privilege-name: monitor-read
EOF
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=kvaughan,ou=People,dc=example,dc=com \
--bindPassword bribery \
--baseDN cn=monitor \
"(ds-cfg-backend-id=dsEvaluation)"
dn: ds-cfg-backend-id=dsEvaluation,cn=backends,cn=monitor
objectClass: top
objectClass: ds-monitor
objectClass: ds-monitor-backend
objectClass: ds-monitor-backend-pluggable
objectClass: ds-monitor-backend-db
ds-cfg-backend-id: dsEvaluation
ds-mon-backend-degraded-index-count: <number>
ds-mon-backend-entry-count: <number>
ds-mon-backend-entry-size-read: <json>
ds-mon-backend-entry-size-written: <json>
ds-mon-backend-filter-indexed: <number>
ds-mon-backend-filter-unindexed: <number>
ds-mon-backend-filter-use-start-time: <timestamp>
ds-mon-backend-is-private: <boolean>
ds-mon-backend-ttl-entries-deleted: <json>
ds-mon-backend-ttl-is-running: <boolean>
ds-mon-backend-ttl-last-run-time: <timestamp>
ds-mon-backend-ttl-queue-size: <number>
ds-mon-backend-ttl-thread-count: <number>
ds-mon-backend-writability-mode: enabled
ds-mon-db-cache-evict-internal-nodes-count: <number>
ds-mon-db-cache-evict-leaf-nodes-count: <number>
ds-mon-db-cache-leaf-nodes: <boolean>
ds-mon-db-cache-misses-internal-nodes: <number>
ds-mon-db-cache-misses-leaf-nodes: <number>
ds-mon-db-cache-size-active: <number>
ds-mon-db-cache-size-total: <number>
ds-mon-db-cache-total-tries-internal-nodes: <number>
ds-mon-db-cache-total-tries-leaf-nodes: <number>
ds-mon-db-checkpoint-count: <number>
ds-mon-db-log-cleaner-file-deletion-count: <number>
ds-mon-db-log-files-open: <number>
ds-mon-db-log-files-opened: <number>
ds-mon-db-log-size-active: <number>
ds-mon-db-log-size-total: <number>
ds-mon-db-log-utilization-max: <number>
ds-mon-db-log-utilization-min: <number>
ds-mon-db-version: <version>JMX-based monitoring
|
The interface stability of the JMX connection handler is Deprecated. JMX MBeans remain supported. |
A number of tools support Java Management Extensions (JMX),
including the jconsole command bundled with the Java platform, and VisualVM.
JMX is not configured by default.
Configure JMX
-
Set server Java arguments appropriately to avoid regular full garbage collection (GC) events.
JMX is based on Java Remote Method Invocation (RMI), which uses references to objects. By default, the JMX client and server perform a full GC periodically to clean up stale references. As a result, the default settings cause JMX to cause a full GC every hour.
To prevent hourly full GCs when using JMX, add the
-XX:+DisableExplicitGCoption to the list ofstart-ds.java-argsarguments. You can do this by editing theconfig/java.propertiesfile and restarting the server.Avoid using this argument when importing LDIF online using the
import-ldifcommand. The import process uses GC to work around memory management issues. -
Configure the server to activate JMX access.
The following example uses the reserved port number,
1689:$ dsconfig \ create-connection-handler \ --handler-name JMX \ --type jmx \ --set enabled:true \ --set listen-port:1689 \ --hostname localhost \ --port 4444 \ --bindDN uid=admin \ --bindPassword password \ --usePkcs12TrustStore /path/to/opendj/config/keystore \ --trustStorePassword:file /path/to/opendj/config/keystore.pin \ --no-promptbashThe change takes effect immediately.
Connect over JMX
-
Add appropriate privileges to access JMX monitoring information.
By default, no users have privileges to access the JMX connection. The following commands create a user with JMX privileges, who can authenticate over an insecure connection:
Show commands
# Create a password policy to allow the user to authenticate insecurely: $ dsconfig \ create-password-policy \ --policy-name "Allow insecure authentication" \ --type password-policy \ --set default-password-storage-scheme:PBKDF2-HMAC-SHA256 \ --set password-attribute:userPassword \ --hostname localhost \ --port 4444 \ --bindDN uid=admin \ --bindPassword password \ --usePkcs12TrustStore /path/to/opendj/config/keystore \ --trustStorePassword:file /path/to/opendj/config/keystore.pin \ --no-prompt # Create a backend for the JMX monitor user entry: $ dsconfig \ create-backend \ --backend-name jmxMonitorUser \ --type ldif \ --set enabled:true \ --set base-dn:"uid=JMX Monitor" \ --set ldif-file:db/jmxMonitorUser/jmxMonitorUser.ldif \ --set is-private-backend:true \ --hostname localhost \ --port 4444 \ --bindDN uid=admin \ --bindPassword password \ --usePkcs12TrustStore /path/to/opendj/config/keystore \ --trustStorePassword:file /path/to/opendj/config/keystore.pin \ --no-prompt # Prepare the JMX monitor user entry. # Notice the privileges and password policy settings: $ cat > /tmp/jmxMonitorUser.ldif << EOF dn: uid=JMX Monitor objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson cn: JMX Monitor sn: User uid: JMX Monitor userPassword: password ds-privilege-name: monitor-read ds-privilege-name: jmx-notify ds-privilege-name: jmx-read ds-privilege-name: jmx-write ds-pwp-password-policy-dn: cn=Allow insecure authentication,cn=Password Policies,cn=config EOF # Import the JMX monitor user: $ import-ldif \ --backendID jmxMonitorUser \ --includeBranch "uid=JMX Monitor" \ --ldifFile /tmp/jmxMonitorUser.ldif \ --hostname localhost \ --port 4444 \ --bindDN uid=admin \ --bindPassword password \ --usePkcs12TrustStore /path/to/opendj/config/keystore \ --trustStorePassword:file /path/to/opendj/config/keystore.pinbash -
Connect using the service URI, username, and password:
- Service URI
-
Full URI to the service including the hostname or IP address and port number for JMX where the DS server listens for connections.
For example, if the server hostname is
localhost, and the DS server listens for JMX connections on port1689, then the service URI is:service:jmx:rmi:///jndi/rmi://localhost:1689/org.opends.server.protocols.jmx.client-unknown
- Username
-
The full DN of the user with privileges to connect over JMX, such as
uid=JMX Monitor. - Password
-
The bind password for the user.
-
Connect remotely.
The following steps show how you connect using VisualVM:
-
Start VisualVM.
-
Select File > Add JMX Connection… to configure the connection:
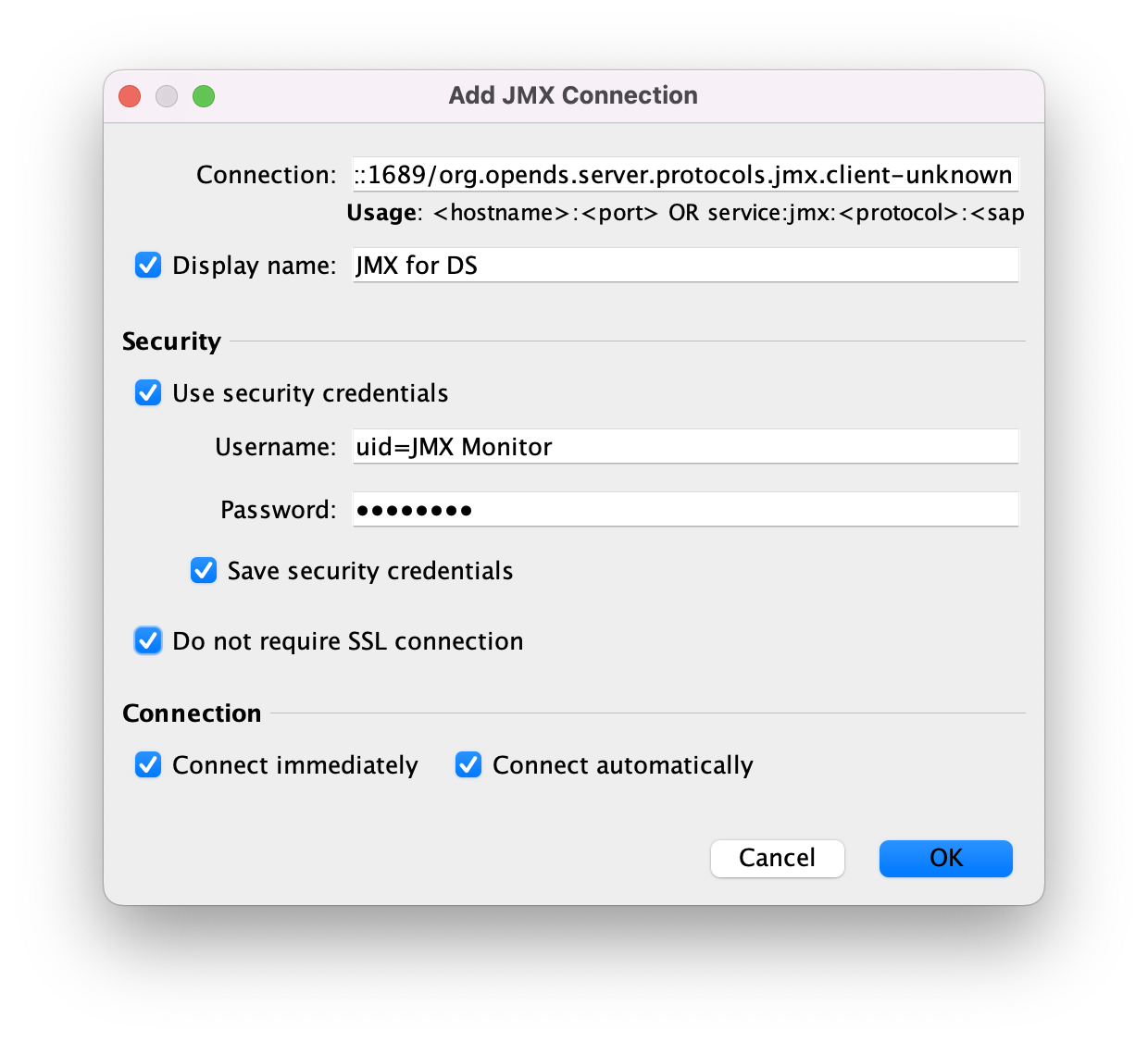
-
Select the connection in the left menu to view JMX monitoring information.
For additional details, refer to Monitoring and Management Using JMX Technology.
-
Status and tasks
The status command functions in offline mode,
but provides more information with the server is running.
The command describes the server’s capabilities, including the ports and disks it uses, and the backends it serves.
With the --script-friendly option, the command returns JSON output.
The command requires administrative credentials to read a running server’s configuration:
$ status \
--bindDn uid=admin \
--bindPassword password \
--hostname localhost \
--port 4444 \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--script-friendlyThe manage-tasks command lets you manage scheduled
server tasks, such as regular backup.
The command connects to the administration port of a local or remote server:
$ manage-tasks \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptPush to Graphite
The Graphite application stores numeric time-series data of the sort produced by monitoring metrics, and allows you to render graphs of that data.
Your applications, in this case DS servers, push data into Graphite.
You do this by configuring the Graphite Monitor Reporter Plugin
with the host and port number of the Graphite service, and with a prefix for your server, such as its FQDN.
By default, the plugin pushes all metrics it produces to the Graphite service.
You can opt to limit this by setting the excluded-metric-pattern or included-metric-pattern properties.
The following example configures the plugin to push metrics to Graphite at graphite.example.com:2004
every 10 seconds (default):
$ dsconfig \
create-plugin \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--plugin-name Graphite \
--type graphite-monitor-reporter \
--set enabled:true \
--set graphite-server:graphite.example.com:2004 \
--set metric-name-prefix:ds.example.com \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptTo view metrics stored in Graphite, you can use the Graphite render API or Grafana, for example. Refer to the Graphite and Grafana documentation for details.
Alerts
DS servers can send alerts for significant server events.
JMX alerts
The following example enables JMX alert notifications:
$ dsconfig \
set-alert-handler-prop \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--handler-name "JMX Alert Handler" \
--set enabled:true \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptMail alerts
The following example sets up an SMTP server, and configures email alerts:
$ dsconfig \
create-mail-server \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--server-name "SMTP server" \
--set enabled:true \
--set auth-username:mail.user \
--set auth-password:password \
--set smtp-server:smtp.example.com:587 \
--set trust-manager-provider:"JVM Trust Manager" \
--set use-start-tls:true \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
$ dsconfig \
create-alert-handler \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--handler-name "SMTP Alert Handler" \
--type smtp \
--set enabled:true \
--set message-subject:"DS Alert, Type: %%alert-type%%, ID: %%alert-id%%" \
--set message-body:"%%alert-message%%" \
--set recipient-address:kvaughan@example.com \
--set sender-address:ds@example.com \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptAlert types
DS servers use the following alert types.
For alert types that indicate server problems, check logs/errors for details:
org.opends.server.AccessControlDisabled-
The access control handler has been disabled.
org.opends.server.AccessControlEnabled-
The access control handler has been enabled.
org.opends.server.authentiation.dseecompat.ACIParseFailed-
The dseecompat access control subsystem failed to correctly parse one or more ACI rules when the server first started.
org.opends.server.BackupFailure-
A backup has failed.
org.opends.server.BackupSuccess-
A backup has completed successfully.
org.opends.server.CannotCopySchemaFiles-
A problem has occurred while attempting to create copies of the existing schema configuration files before making a schema update, and the schema configuration has been left in a potentially inconsistent state.
org.opends.server.CannotRenameCurrentTaskFile-
The server is unable to rename the current tasks backing file in the process of trying to write an updated version.
org.opends.server.CannotRenameNewTaskFile-
The server is unable to rename the new tasks backing file into place.
org.opends.server.CannotScheduleRecurringIteration-
The server is unable to schedule an iteration of a recurring task.
org.opends.server.CannotWriteConfig-
The server is unable to write its updated configuration for some reason and therefore the server may not exhibit the new configuration if it is restarted.
org.opends.server.CannotWriteNewSchemaFiles-
A problem has occurred while attempting to write new versions of the server schema configuration files, and the schema configuration has been left in a potentially inconsistent state.
org.opends.server.CannotWriteTaskFile-
The server is unable to write an updated tasks backing file for some reason.
org.opends.server.DirectoryServerShutdown-
The server has begun the process of shutting down.
org.opends.server.DirectoryServerStarted-
The server has completed its startup process.
org.opends.server.DiskFull-
Free disk space has reached the full threshold.
Default is 6% of the size of the file system.
org.opends.server.DiskSpaceLow-
Free disk space has reached the low threshold.
Default is 10% of the size of the file system.
org.opends.server.EnteringLockdownMode-
The server is entering lockdown mode, wherein only root users are allowed to perform operations and only over the loopback address.
org.opends.server.LDAPHandlerDisabledByConsecutiveFailures-
Consecutive failures have occurred in the LDAP connection handler and have caused it to become disabled.
org.opends.server.LDAPHandlerUncaughtError-
Uncaught errors in the LDAP connection handler have caused it to become disabled.
org.opends.server.LDIFBackendCannotWriteUpdate-
An LDIF backend was unable to store an updated copy of the LDIF file after processing a write operation.
org.opends.server.LDIFConnectionHandlerIOError-
The LDIF connection handler encountered an I/O error that prevented it from completing its processing.
org.opends.server.LDIFConnectionHandlerParseError-
The LDIF connection handler encountered an unrecoverable error while attempting to parse an LDIF file.
org.opends.server.LeavingLockdownMode-
The server is leaving lockdown mode.
org.opends.server.ManualConfigEditHandled-
The server detects that its configuration has been manually edited with the server online, and those changes were overwritten by another change made through the server. The manually edited configuration will be copied to another location.
org.opends.server.ManualConfigEditLost-
The server detects that its configuration has been manually edited with the server online, and those changes were overwritten by another change made through the server. The manually edited configuration could not be preserved due to an unexpected error.
org.opends.server.replication.UnresolvedConflict-
Multimaster replication cannot resolve a conflict automatically.
org.opends.server.UncaughtException-
A server thread has encountered an uncaught exception that caused that thread to terminate abnormally. The impact that this problem has on the server depends on which thread was impacted and the nature of the exception.
org.opends.server.UniqueAttributeSynchronizationConflict-
A unique attribute conflict has been detected during synchronization processing.
org.opends.server.UniqueAttributeSynchronizationError-
An error occurred while attempting to perform unique attribute conflict detection during synchronization processing.
Metric types reference
The following monitoring metrics are available in each interface:
| Type | Description |
|---|---|
Counter |
Cumulative metric for a numerical value that only increases while the server is running. Counts that reflect volatile data, such as the number of requests, are reset to 0 when the server starts up. |
Gauge |
Metric for a numerical value that can increase or decrease. |
Histogram |
Metric that samples observations, and counts them in buckets, as well as providing a sum of all observed values. LDAP metrics show histograms as JSON objects. JSON histograms for entry sizes (in bytes) have the following fields:(1) |
Summary |
Metric that samples observations, providing a count of observations, sum total of observed amounts, average rate of events, and moving average rates across sliding time windows. LDAP metrics show summaries as JSON objects. JSON summaries have the following fields:(1) The The Prometheus view does not provide time-based statistics, as rates can be calculated from the time-series data. Instead, the Prometheus view includes summary metrics whose names have the following suffixes or labels:
|
Timer |
Metric combining a summary with other statistics. LDAP metrics show summaries as JSON objects. JSON summaries have the following fields(1) The Prometheus view does not provide time-based statistics. Rates can be calculated from the time-series data. |
(1) Monitoring metrics reflect sample observations made while the server is running. The values are not saved when the server shuts down. As a result, metrics of this type reflect data recorded since the server started.
Metrics that show etime measurements in milliseconds (ms) continue to show values in ms even if the server is configured to log etimes in nanoseconds.
The calculation of moving averages is intended to be the same
as that of the uptime and top commands,
where the moving average plotted over time is smoothed by weighting that decreases exponentially.
For an explanation of the mechanism, refer to the Wikipedia section,
Exponential moving average.
LDAP metrics reference
LDAP metrics are exposed as LDAP attributes on entries under cn=monitor.
Metrics entry object class names start with ds-monitor.
Metrics attribute names start with ds-mon.
For details, refer to the About This Reference.
For examples of common monitoring requests, refer to LDAP-based monitoring.
|
Some |
| Name | Syntax | Description |
|---|---|---|
|
Counter metric |
Total number of abandoned operations since startup |
|
Integer |
Number of active client connections |
|
Integer |
Number of active persistent searches |
|
Integer |
Number of connections currently established on the Administration Connector |
|
Host port |
The administrative host and port |
|
Directory String |
Certificate alias |
|
Boolean |
Indicates whether the server is alive |
|
Directory String |
Lists server errors preventing the server from operating correctly that require administrative action |
|
Directory String |
Backend degraded index |
|
Integer |
Number of degraded indexes in the backend |
|
Integer |
Number of entries contained in the backend |
|
Summary metric |
Histogram of entry sizes being read from the underlying storage |
|
Summary metric |
Histogram of entry sizes being written to the underlying storage |
|
Integer |
Number of indexed searches performed against the backend |
|
Integer |
Number of unindexed searches performed against the backend |
|
Json |
Information about the simple search filter processed against the backend |
|
Generalized Time |
Time the server started recording statistical information about the simple search filters processed against the backend |
|
Boolean |
Whether the base DNs of this backend should be considered public or private |
|
DN |
Base DNs routed to remote LDAP servers by the proxy backend |
|
Summary metric |
Remote LDAP servers that the proxy backend forwards requests to |
|
Summary metric |
Summary for entries purged by time-to-live |
|
Boolean |
Indicates whether time-to-live is in the process of purging expired entries |
|
Generalized Time |
Last time time-to-live finished purging expired entries |
|
Integer |
Number of entries queued for purging by the time-to-live service |
|
Integer |
Number of active time-to-live threads |
|
Directory String |
Current backend behavior when processing write operations, can either be "disabled", "enabled" or "internal-only" |
|
DN |
Base DN handled by a backend |
|
Integer |
Number of subordinate entries of the base DN, including the base DN |
|
Integer |
Build number of the Directory Server |
|
Directory String |
Build date and time of the Directory Server |
|
Summary metric |
Network bytes read summary |
|
Summary metric |
Network bytes written summary |
|
Integer |
Current number of entries held in this cache |
|
Integer |
Maximum number of entries allowed in this cache |
|
Size in bytes |
Memory limit for this cache |
|
Summary metric |
Number of attempts to retrieve an entry that was not held in this cache |
|
Integer |
Total memory in bytes used by this cache |
|
Summary metric |
Number of attempts to retrieve an entry from this cache |
|
Generalized Time |
Time the certificate expires |
|
DN |
Certificate issuer DN |
|
Integer |
Certificate serial number |
|
DN |
Certificate subject DN |
|
Integer |
The number of changelog files containing updates generated by this replica. A value of zero indicates the replica did not generate any updates during the last purge delay interval |
|
Host port |
The host and port of the changelog server |
|
Directory String |
Changelog identifier |
|
Duration in milli-seconds |
The purge delay of the changelog |
|
Integer |
Total number of collective attribute subentries |
|
Directory String |
Compact version of the Directory Server |
|
DN |
DN of the configuration entry |
|
Host port |
Host and replication port of the server that this server is connected to |
|
Directory String |
Identifier of the server that this server is connected to |
|
Json |
Client connection summary information |
|
Summary metric |
Connection summary |
|
Integer |
Number of client connections currently established except on the Administration Connector |
|
Integer |
Current replication window size for receiving messages, indicating the number of replication messages a remote server can send before waiting on acknowledgement from this server. This does not depend on the TCP window size |
|
Generalized Time |
Current time |
|
Integer |
Number of internal nodes evicted from the database cache |
|
Integer |
Number of leaf nodes (data records) evicted from the database cache |
|
Boolean |
Whether leaf nodes are cached |
|
Integer |
Number of internal nodes requested by btree operations that were not in the database cache |
|
Integer |
Number of leaf nodes (data records) requested by btree operations that were not in the database cache |
|
Size in bytes |
Size of the database cache |
|
Size in bytes |
Maximum size of the database cache |
|
Integer |
Number of internal nodes requested by btree operations |
|
Integer |
Number of leaf nodes (data records) requested by btree operations |
|
Integer |
Number of checkpoints run so far |
|
Integer |
Number of cleaner file deletions |
|
Integer |
Number of files currently open in the database file cache |
|
Integer |
Number of times a log file has been opened |
|
Size in bytes |
Estimate of the amount in bytes of live data in all data files (i.e., the size of the DB, ignoring garbage) |
|
Size in bytes |
Size used by all data files on disk |
|
Integer |
Current maximum (upper bound) log utilization as a percentage |
|
Integer |
Current minimum (lower bound) log utilization as a percentage |
|
Directory String |
Database version used by the backend |
|
Filesystem path |
A monitored directory containing data that may change over time |
|
Size in bytes |
Amount of free disk space |
|
Size in bytes |
Effective full disk space threshold |
|
Size in bytes |
Effective low disk space threshold |
|
Filesystem path |
Monitored disk root |
|
Directory String |
Current disk state, can be either "normal", "low" or "full" |
|
Integer |
Replication domain generation identifier |
|
DN |
Replication domain name |
|
Integer |
Total number of dynamic groups |
|
Integer |
Total number of entries ACIs |
|
Integer |
Number of entries for which an update operation has been received but not replayed yet by this replica |
|
Integer |
Total number of entries with ACI attributes |
|
Directory String |
IDs of issues that have been fixed in this Directory Server build |
|
Directory String |
Full version of the Directory Server |
|
Integer |
Total number of global ACIs |
|
Directory String |
Unique identifier of the group in which the directory server belongs |
|
Boolean |
Indicates whether the server is able to handle requests |
|
Directory String |
Lists transient server errors preventing the server from temporarily handling requests |
|
Directory String |
The name of the index |
|
Timer metric |
Number of index updates and their time cost |
|
Directory String |
Change number indexing state, can be one of "INDEXING", "BLOCKED_BY_REPLICA_NOT_IN_TOPOLOGY" or "WAITING_ON_UPDATE_FROM_REPLICA" |
|
Summary metric |
Number of accesses of this index. For attribute indexes it represents the number of search operations that have used this index, for system indexes it represents the number of key lookups. |
|
Filesystem path |
Directory Server root installation path |
|
Filesystem path |
Directory Server instance path |
|
Directory String |
Java virtual machine architecture (e.g. 32-bit, 64-bit) |
|
Directory String |
Input arguments passed to the Java virtual machine |
|
Integer |
Number of processors available to the Java virtual machine |
|
Integer |
Number of classes loaded since the Java virtual machine started |
|
Integer |
Number of classes unloaded since the Java virtual machine started |
|
Filesystem path |
Path used to find directories and JAR archives containing Java class files |
|
Filesystem path |
Installation directory for Java runtime environment (JRE) |
|
Directory String |
Java runtime environment (JRE) vendor |
|
Directory String |
Java runtime environment (JRE) version |
|
Size in bytes |
Amount of heap memory that the Java virtual machine initially requested from the operating system |
|
Size in bytes |
Maximum amount of heap memory that the Java virtual machine will attempt to use |
|
Size in bytes |
Amount of heap memory that is committed for the Java virtual machine to use |
|
Size in bytes |
Amount of heap memory used by the Java virtual machine |
|
Size in bytes |
Amount of memory that the Java virtual machine initially requested from the operating system |
|
Size in bytes |
Maximum amount of memory that the Java virtual machine will attempt to use |
|
Size in bytes |
Amount of non-heap memory that the Java virtual machine initially requested from the operating system |
|
Size in bytes |
Maximum amount of non-heap memory that the Java virtual machine will attempt to use |
|
Size in bytes |
Amount of non-heap memory that is committed for the Java virtual machine to use |
|
Size in bytes |
Amount of non-heap memory used by the Java virtual machine |
|
Size in bytes |
Amount of memory that is committed for the Java virtual machine to use |
|
Size in bytes |
Amount of memory used by the Java virtual machine |
|
Directory String |
Transport Layer Security (TLS) cipher suites supported by this Directory Server |
|
Directory String |
Transport Layer Security (TLS) protocols supported by this Directory Server |
|
Integer |
Number of threads in the BLOCKED state |
|
Integer |
Number of live threads including both daemon and non-daemon threads |
|
Integer |
Number of live daemon threads |
|
Integer |
Number of deadlocked threads |
|
Directory String |
Diagnostic stack traces for deadlocked threads |
|
Integer |
Number of threads in the NEW state |
|
Integer |
Number of threads in the RUNNABLE state |
|
Integer |
Number of threads in the TERMINATED state |
|
Integer |
Number of threads in the TIMED_WAITING state |
|
Integer |
Number of threads in the WAITING state |
|
Directory String |
Java virtual machine vendor |
|
Directory String |
Java virtual machine version |
|
Directory String |
The CSN of the last received update originating from the remote replica |
|
Directory String |
The CSN of the last replayed update originating from the remote replica |
|
Generalized Time |
Time this server was last seen |
|
Host port |
The host and port to connect using LDAP (no support for start TLS) |
|
Host port |
The host and port to connect using LDAPS |
|
Host port |
The host and port to connect using LDAP (with support for start TLS) |
|
Directory String |
Host and port |
|
Integer |
Number of times the replica lost its connection to the replication server |
|
Integer |
Major version number of the Directory Server |
|
Integer |
Maximum number of simultaneous client connections that have been established with the Directory Server |
|
Integer |
Minor version number of the Directory Server |
|
Integer |
Newest change number present in the change number index database |
|
CSN (Change Sequence Number) |
Newest CSN present in the replica database |
|
Generalized Time |
Time of the newest CSN present in the replica database |
|
Integer |
Oldest change number present in the change number index database |
|
CSN (Change Sequence Number) |
Oldest CSN present in the replica database |
|
Generalized Time |
Time of the oldest CSN present in the replica database |
|
Directory String |
Operating system architecture |
|
Directory String |
Operating system name |
|
Directory String |
Operating system version |
|
Integer |
Total number of password policy subentries |
|
Integer |
Point version number of the Directory Server |
|
UUID |
Process ID of the running directory server |
|
Directory String |
Full name of the Directory Server |
|
Directory String |
Network protocol |
|
Boolean |
Indicates whether changelog purging is waiting for change number indexing to advance. If true, check the ds-mon-indexing-state and ds-mon-replicas-preventing-indexing metrics |
|
Duration in milli-seconds |
Current local delay in receiving replicated operations |
|
Duration in milli-seconds |
Current local delay in replaying replicated operations |
|
Counter metric |
Number of updates replayed on this replica which modify the internal state but not user data |
|
Timer metric |
Replay etime for updates that have been replayed on this replica |
|
Counter metric |
Number of updates replayed on this replica for which replication naming conflicts have been resolved |
|
Counter metric |
Number of updates replayed on this replica for which replication naming conflicts have not been resolved |
|
Directory String |
Lists the replicas preventing external changelog change numbers from incrementing |
|
DN |
The replication domain |
|
Integer |
The protocol version used for replication |
|
Timer metric |
Abandon request timer |
|
Timer metric |
Add request timer |
|
Timer metric |
Bind request timer |
|
Timer metric |
Compare request timer |
|
Timer metric |
Delete request timer |
|
Timer metric |
Extended request timer |
|
Timer metric |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Timer metric |
Timer for requests that could not complete because further action is required (associated HTTP status codes: redirection (3xx)) |
|
Timer metric |
Timer for requests that failed because the server did not hold the request targeted entry (but was able to provide alternative servers that may) (associated LDAP result code: 10) |
|
Timer metric |
Timer for requests that failed because they were trying to exceed the resource limits allocated to the associated clients (associated LDAP result codes: time, size and admin limit exceeded (respectively 4, 5 and 11) |
|
Timer metric |
Timer for requests that failed for security reasons (associated LDAP result codes: 8, 9, 13, 25, 26, 27; associated HTTP status codes: unauthorized (401) and forbidden (403)) |
|
Timer metric |
Timer for apparently valid requests that failed because the server was not able to process them (associated LDAP result codes: busy (51), unavailable (52), unwilling to perform (53) and other (80); associated HTTP status codes: server error (5xx)) |
|
Timer metric |
Timer for requests that failed due to uncategorized reasons |
|
Timer metric |
GET request timer |
|
Integer |
Number of requests in the work queue that have not yet been picked up for processing |
|
Timer metric |
Modify request timer |
|
Timer metric |
Modify DN request timer |
|
Timer metric |
PATCH request timer |
|
Timer metric |
POST request timer |
|
Timer metric |
Persistent search request timer |
|
Timer metric |
PUT request timer |
|
Timer metric |
Base object search request timer |
|
Timer metric |
One level search request timer |
|
Timer metric |
Subtree search request timer |
|
Summary metric |
Summary for operations that have been successfully submitted to the work queue |
|
Timer metric |
Unbind request timer |
|
Timer metric |
Uncategorized request timer |
|
Directory String |
Revision ID in the source repository from which the Directory Server is build |
|
Counter metric |
Number of replication updates sent by this replica |
|
Directory String |
Server identifier |
|
Boolean |
Indicates whether this is the topology server that has handled the monitoring request |
|
CSN (Change Sequence Number) |
Replication server state |
|
Directory String |
Short name of the Directory Server |
|
Boolean |
Whether SSL encryption is used when exchanging messages with this server |
|
Generalized Time |
Time the Directory Server started |
|
Integer |
Total number of static groups |
|
Integer |
Number of static groups with at most 100 members |
|
Integer |
Number of static groups with at most 1000 members |
|
Integer |
Number of static groups with at most 10000 members |
|
Integer |
Number of static groups with at most 100000 members |
|
Integer |
Number of static groups with at most 1000000 members |
|
Integer |
Total number of static groups |
|
Directory String |
Replication status of the local replica, can either be "Invalid", "Not connected", "Normal", "Too late", "Full update", "Bad data" |
|
Generalized Time |
Last time the replication status of the local replica changed |
|
Directory String |
Supported server log categories |
|
Directory String |
Fully qualified domain name of the system where the Directory Server is running |
|
Duration in milli-seconds |
Duration since the last time a change was indexed |
|
Integer |
Total number of client connections that have been established with the Directory Server since it started |
|
Directory String |
The type of total update when it is in progress. Possible values: import or export |
|
Integer |
The total number of entries to be processed when a total update is in progress |
|
Integer |
The number of entries still to be processed when a total update is in progress |
|
Counter metric |
Number of duplicate updates: updates received by this replica which cannot be applied because they are already in progress. Can happen when a directory server fails over to another replication server |
|
Integer |
Number of remote updates received from the replication server but not replayed yet on this replica |
|
Integer |
Number of remote updates received in the queue waiting to be replayed |
|
Integer |
Number of remote updates received in the queue |
|
Integer |
Number of local updates that are waiting to be sent to the replication server once they complete |
|
Json |
JSON array of the number of updates replayed per replay thread |
|
Directory String |
Vendor name of the Directory Server |
|
Directory String |
Version qualifier of the Directory Server |
|
Integer |
Total number of virtual static groups |
|
Filesystem path |
Current working directory of the user running the Directory Server |
Prometheus metrics reference
This page lists Prometheus metrics:
-
This page shows labels in braces; for example, the labels in
ds_backend_db_cache_misses_internal_nodes{backend,type}arebackendandtype. -
Time gauges whose names end in
_secondsindicate seconds since 1 Jan 1970 UTC; for exampleds_current_time_seconds 1679472039means Wed, 22 Mar 2023 08:00:39.
For examples of common monitoring requests, refer to HTTP-based monitoring.
|
Some |
| Name | Type | Description |
|---|---|---|
|
Gauge |
Total number of ACIs of the specified type |
|
Gauge |
Number of connections currently established on the Administration Connector |
|
Gauge |
Current number of entries held in this cache |
|
Summary |
Number of attempts to retrieve an entry that was not held in this cache |
|
Summary |
Number of attempts to retrieve an entry that was not held in this cache |
|
Gauge |
Total memory in bytes used by this cache |
|
Summary |
Number of attempts to retrieve an entry from this cache |
|
Summary |
Number of attempts to retrieve an entry from this cache |
|
Gauge |
Number of internal nodes evicted from the database cache |
|
Gauge |
Number of leaf nodes (data records) evicted from the database cache |
|
Gauge |
Whether leaf nodes are cached |
|
Gauge |
Number of internal nodes requested by btree operations that were not in the database cache |
|
Gauge |
Number of leaf nodes (data records) requested by btree operations that were not in the database cache |
|
Gauge |
Size of the database cache |
|
Gauge |
Maximum size of the database cache |
|
Gauge |
Number of internal nodes requested by btree operations |
|
Gauge |
Number of leaf nodes (data records) requested by btree operations |
|
Gauge |
Number of checkpoints run so far |
|
Gauge |
Number of cleaner file deletions |
|
Gauge |
Number of times a log file has been opened |
|
Gauge |
Number of files currently open in the database file cache |
|
Gauge |
Estimate of the amount in bytes of live data in all data files (i.e., the size of the DB, ignoring garbage) |
|
Gauge |
Size used by all data files on disk |
|
Gauge |
Current maximum (upper bound) log utilization as a percentage |
|
Gauge |
Current minimum (lower bound) log utilization as a percentage |
|
Gauge |
Number of degraded indexes in the backend |
|
Gauge |
Number of subordinate entries of the base DN, including the base DN |
|
Histogram |
Histogram of entry sizes being read from the underlying storage |
|
Histogram |
Histogram of entry sizes being read from the underlying storage |
|
Histogram |
Histogram of entry sizes being read from the underlying storage |
|
Histogram |
Histogram of entry sizes being written to the underlying storage |
|
Histogram |
Histogram of entry sizes being written to the underlying storage |
|
Histogram |
Histogram of entry sizes being written to the underlying storage |
|
Gauge |
Number of indexed searches performed against the backend |
|
Gauge |
Number of unindexed searches performed against the backend |
|
Gauge |
Time the server started recording statistical information about the simple search filters processed against the backend |
|
Summary |
Number of index updates and their time cost |
|
Summary |
Number of index updates and their time cost |
|
Summary |
Number of index updates and their time cost |
|
Summary |
Number of accesses of this index. For attribute indexes it represents the number of search operations that have used this index, for system indexes it represents the number of key lookups. |
|
Summary |
Number of accesses of this index. For attribute indexes it represents the number of search operations that have used this index, for system indexes it represents the number of key lookups. |
|
Gauge |
Whether the base DNs of this backend should be considered public or private |
|
Summary |
Summary for entries purged by time-to-live |
|
Summary |
Summary for entries purged by time-to-live |
|
Gauge |
Indicates whether time-to-live is in the process of purging expired entries |
|
Gauge |
Last time time-to-live finished purging expired entries |
|
Gauge |
Number of entries queued for purging by the time-to-live service |
|
Gauge |
Number of active time-to-live threads |
|
Gauge |
Time the certificate expires |
|
Gauge |
Refer to the indexing_state dimension for details |
|
Gauge |
Duration since the last time a change was indexed |
|
Gauge |
Number of active client connections |
|
Summary |
Network bytes read summary |
|
Summary |
Network bytes read summary |
|
Summary |
Network bytes written summary |
|
Summary |
Network bytes written summary |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Counter |
Total number of abandoned operations since startup |
|
Counter |
Total number of abandoned operations since startup |
|
Gauge |
Number of active client connections |
|
Gauge |
Number of active persistent searches |
|
Summary |
Network bytes read summary |
|
Summary |
Network bytes read summary |
|
Summary |
Network bytes written summary |
|
Summary |
Network bytes written summary |
|
Summary |
Connection summary |
|
Summary |
Connection summary |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for requests that failed because there was a problem while attempting to perform the associated operation (associated LDAP result codes: 1, 2, 12, 15, 16, 17, 18, 19, 20, 21, 23, 34, 35, 36, 37, 38, 39; associated HTTP status codes: client error (4xx) except 401 and 403) |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Summary |
Timer for the specified request type |
|
Gauge |
Number of client connections currently established except on the Administration Connector |
|
Gauge |
Current time |
|
Gauge |
Amount of free disk space |
|
Gauge |
Effective full disk space threshold |
|
Gauge |
Effective low disk space threshold |
|
Gauge |
Total number of entries with ACI attributes |
|
Gauge |
Current number of entries held in this cache |
|
Gauge |
Maximum number of entries allowed in this cache |
|
Gauge |
Memory limit for this cache |
|
Summary |
Number of attempts to retrieve an entry that was not held in this cache |
|
Summary |
Number of attempts to retrieve an entry that was not held in this cache |
|
Gauge |
Total memory in bytes used by this cache |
|
Summary |
Number of attempts to retrieve an entry from this cache |
|
Summary |
Number of attempts to retrieve an entry from this cache |
|
Gauge |
Total number of groups of the specified type |
|
Gauge |
Indicates whether the server is alive |
|
Gauge |
Indicates whether the server is able to handle requests |
|
Gauge |
Number of processors available to the Java virtual machine |
|
Gauge |
Number of classes loaded since the Java virtual machine started |
|
Gauge |
Number of classes unloaded since the Java virtual machine started |
|
Gauge |
Amount of heap memory that the Java virtual machine initially requested from the operating system |
|
Gauge |
Maximum amount of heap memory that the Java virtual machine will attempt to use |
|
Gauge |
Amount of heap memory that is committed for the Java virtual machine to use |
|
Gauge |
Amount of heap memory used by the Java virtual machine |
|
Gauge |
Amount of memory that the Java virtual machine initially requested from the operating system |
|
Gauge |
Maximum amount of memory that the Java virtual machine will attempt to use |
|
Gauge |
Amount of non-heap memory that the Java virtual machine initially requested from the operating system |
|
Gauge |
Maximum amount of non-heap memory that the Java virtual machine will attempt to use |
|
Gauge |
Amount of non-heap memory that is committed for the Java virtual machine to use |
|
Gauge |
Amount of non-heap memory used by the Java virtual machine |
|
Gauge |
Amount of memory that is committed for the Java virtual machine to use |
|
Gauge |
Amount of memory used by the Java virtual machine |
|
Gauge |
Number of threads in the BLOCKED state |
|
Gauge |
Number of live threads including both daemon and non-daemon threads |
|
Gauge |
Number of live daemon threads |
|
Gauge |
Number of deadlocked threads |
|
Gauge |
Number of threads in the NEW state |
|
Gauge |
Number of threads in the RUNNABLE state |
|
Gauge |
Number of threads in the TERMINATED state |
|
Gauge |
Number of threads in the TIMED_WAITING state |
|
Gauge |
Number of threads in the WAITING state |
|
Gauge |
Maximum number of simultaneous client connections that have been established with the Directory Server |
|
Gauge |
Current replication window size for receiving messages, indicating the number of replication messages a remote server can send before waiting on acknowledgement from this server. This does not depend on the TCP window size |
|
Gauge |
Replication domain generation identifier |
|
Gauge |
Whether SSL encryption is used when exchanging messages with this server |
|
Gauge |
Current replication window size for receiving messages, indicating the number of replication messages a remote server can send before waiting on acknowledgement from this server. This does not depend on the TCP window size |
|
Gauge |
Replication domain generation identifier |
|
Gauge |
Whether SSL encryption is used when exchanging messages with this server |
|
Gauge |
Replication domain generation identifier |
|
Gauge |
Newest change number present in the change number index database |
|
Gauge |
Oldest change number present in the change number index database |
|
Gauge |
Indicates whether changelog purging is waiting for change number indexing to advance. If true, check the ds-mon-indexing-state and ds-mon-replicas-preventing-indexing metrics |
|
Gauge |
The number of changelog files containing updates generated by this replica. A value of zero indicates the replica did not generate any updates during the last purge delay interval |
|
Gauge |
Time of the newest CSN present in the replica database |
|
Gauge |
Time of the oldest CSN present in the replica database |
|
Gauge |
Current replication window size for receiving messages, indicating the number of replication messages a remote server can send before waiting on acknowledgement from this server. This does not depend on the TCP window size |
|
Gauge |
Replication domain generation identifier |
|
Gauge |
Number of entries for which an update operation has been received but not replayed yet by this replica |
|
Gauge |
Number of times the replica lost its connection to the replication server |
|
Gauge |
Current local delay in receiving replicated operations |
|
Gauge |
Current local delay in replaying replicated operations |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Gauge |
Number of remote updates received in the queue waiting to be replayed |
|
Gauge |
Number of remote updates received in the queue |
|
Counter |
Number of updates replayed on this replica which modify the internal state but not user data |
|
Counter |
Number of updates replayed on this replica which modify the internal state but not user data |
|
Counter |
Number of updates replayed on this replica for which replication naming conflicts have been resolved |
|
Counter |
Number of updates replayed on this replica for which replication naming conflicts have been resolved |
|
Counter |
Number of updates replayed on this replica for which replication naming conflicts have not been resolved |
|
Counter |
Number of updates replayed on this replica for which replication naming conflicts have not been resolved |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Summary |
Replay etime for updates that have been replayed on this replica |
|
Counter |
Number of replication updates sent by this replica |
|
Gauge |
Whether SSL encryption is used when exchanging messages with this server |
|
Gauge |
Last time the replication status of the local replica changed |
|
Gauge |
Status of the specified replica |
|
Gauge |
The total number of entries to be processed when a total update is in progress |
|
Gauge |
The number of entries still to be processed when a total update is in progress |
|
Counter |
Number of duplicate updates: updates received by this replica which cannot be applied because they are already in progress. Can happen when a directory server fails over to another replication server |
|
Counter |
Number of duplicate updates: updates received by this replica which cannot be applied because they are already in progress. Can happen when a directory server fails over to another replication server |
|
Gauge |
Number of remote updates received from the replication server but not replayed yet on this replica |
|
Gauge |
Number of local updates that are waiting to be sent to the replication server once they complete |
|
Gauge |
Time the Directory Server started |
|
Gauge |
Number of static groups with at most the specified number of members |
|
Gauge |
Total number of LDAP subentries of the specified type |
|
Gauge |
Indicates whether this is the topology server that has handled the monitoring request |
|
Gauge |
Total number of client connections that have been established with the Directory Server since it started |
|
Gauge |
Number of requests in the work queue that have not yet been picked up for processing |
|
Summary |
Summary for operations that have been successfully submitted to the work queue |
|
Summary |
Summary for operations that have been successfully submitted to the work queue |