Scripting
Guide to scripting for ForgeRock® Identity Management.
Scripting lets you extend IDM functionality. For example, you can provide custom logic between source and target mappings, define correlation rules, filters, triggers, and so on. This guide shows you how to use scripts in IDM and provides reference information on the script engine.
IDM supports scripts written in JavaScript and Groovy, and uses the following libraries:
-
Rhino version 1.7.14 to run JavaScript.
Rhino has limited support for ES6 / ES2015 (JavaScript version 1.7). For more information, refer to Rhino ES2015 Support. -
Groovy version 3.0.9 for Groovy script support.
-
Lodash 3.10.1 and Handlebars 4.7.7 for Rhino scripting.
Using Handlebars JS in server-side JS scripts requires synchronization; for example:
var Handlebars = require("lib/handlebars"); var result = new Packages.org.mozilla.javascript.Synchronizer(function() { var template = Handlebars.compile("Handlebars {{doesWhat}}"); return template({ doesWhat: "rocks!" }); }, Handlebars)(); console.log(result);javascript -
BouncyCastle 1.70 for signing JWTs.
The BouncyCastle .JAR file that is bundled with IDM includes the org.bouncycastle.asn1.util.Dumpcommand-line utility. Although this utility is not used directly by IDM, it is possible to reference the utility in your scripts. Due to a security vulnerability in this utility, you should not reference it in your scripts. For more information, refer to the corresponding BouncyCastle issue.
|
Script options and locations are defined in the script configuration. Default scripts are located in ( |
ForgeRock Identity Platform™ serves as the basis for our simple and comprehensive Identity and Access Management solution. We help our customers deepen their relationships with their customers, and improve the productivity and connectivity of their employees and partners. For more information about ForgeRock and about the platform, refer to https://www.forgerock.com.
The ForgeRock Common REST API works across the platform to provide common ways to access web resources and collections of resources.
Script configuration
To modify the parameters used for compiling, debugging, and running scripts, edit the script configuration.
- properties
-
Any custom properties.
- ECMAScript
-
JavaScript debug and compile options. JavaScript is an ECMAScript language.
-
javascript.optimization.level- The current optimization level. Expected integer range is from -1 to 9. For more information about optimization level, refer to Rhino Optimization.The default value is
9. -
javascript.recompile.minimumInterval- The minimum time between script recompile.The default value is
60000, or 60 seconds. This means that any changes made to scripts will not get picked up for up to 60 seconds. If you are developing scripts, reduce this parameter to around100(100 milliseconds).If you set the
javascript.recompile.minimumIntervalto-1, or remove this property from the script configuration, IDM does not poll JavaScript files to check for changes.
-
- Groovy
-
Compilation and debugging options related to Groovy scripts. Many of these options are commented out in the default script configuration file. Remove the comments to set these properties:
-
groovy.warnings- The Groovy script log level. Possible values arenone,likely,possible, andparanoia. -
groovy.source.encoding- The Groovy script encoding format. Possible values areUTF-8andUS-ASCII. -
groovy.target.directory- The compiled Groovy class output directory. The default directory isinstall-dir/classes. -
groovy.target.bytecode- The Groovy script bytecode version. The default version is1.5. -
groovy.classpath- The directory where the compiler should look for compiled classes. The default classpath isinstall-dir/lib.To call an external library from a Groovy script, you must specify the complete path to the .jar file or files, as a value of this property. For example:
"groovy.classpath" : "/&{idm.install.dir}/lib/http-builder-0.7.1.jar: /&{idm.install.dir}/lib/json-lib-2.3-jdk15.jar: /&{idm.install.dir}/lib/xml-resolver-1.2.jar: /&{idm.install.dir}/lib/commons-collections-3.2.1.jar",groovyIf you’re deploying on Microsoft Windows, use a semicolon ( ;) instead of a colon to separate directories in thegroovy.classpath. -
groovy.output.verbose- Verbosity of stack traces. Boolean,trueorfalse. -
groovy.output.debug- Whether to output debug messages. Boolean, `true ` orfalse. -
groovy.errors.tolerance- The number of non-fatal errors that can occur before a compilation is aborted. The default is10errors. -
groovy.script.extension- Groovy script file extension. The default is.groovy. -
groovy.script.base- Groovy script base class. By default, any class extendsgroovy.lang.Script. -
groovy.recompile- Whether scripts can be recompiled. Boolean,trueorfalse, with defaulttrue. -
groovy.recompile.minimumInterval- Groovy script minimum recompile interval.The default value is
60000, or 60 seconds. Using the default value, any changes made to scripts may not be in effect for up to 60 seconds. If you are developing scripts, reduce this parameter to100(100 milliseconds). -
groovy.target.indy- Whether to use a Groovy indy test. Boolean,trueorfalse, with defaulttrue. -
groovy.disabled.global.ast.transformations- A list of disabled Abstract Syntax Transformations (ASTs).
-
- sources
-
The directories where IDM looks for referenced scripts.
Excerpt of a script configuration displaying default directories:
"sources" : { "default" : { "directory" : "&{idm.install.dir}/bin/defaults/script" }, "install" : { "directory" : "&{idm.install.dir}" }, "project" : { "directory" : "&{idm.instance.dir}" }, "project-script" : { "directory" : "&{idm.instance.dir}/script" }jsonIDM loads scripts from
sourcesin reverse order (bottom to top).
|
By default, debug information (for example, file name and line number) is excluded from JavaScript and Groovy exceptions. To troubleshoot script exceptions, you can include debug information by changing the following settings to properties Including debug information in a production environment is not recommended. |
Call a script from the IDM configuration
To call a script from the IDM configuration, edit the configuration object. For example:
{
"type" : "text/javascript",
"source": "scriptSource",
"resourceBindings" : [{
"resource" : "resourceName",
"version" : "1.0",
"binding" : "customName"
}]
}or
{
"type" : "text/javascript",
"file" : "file location"
}Script variables are not necessarily simple key:value pairs, and can be any arbitrarily complex JSON object.
- type
-
string, required
The script type.
IDM supports
"text/javascript"and"groovy". - source
-
string, required if
fileis not specifiedSpecifies the source code of the script to be executed.
- resourceBindings
-
JSON object, optional
Allows specifying a resource, a vanity binding for that resource, and the API version the script should use. For example:
{ "source" : "var response = consent.action(\"getConsentMappings\", {}); response[0];", "resourceBindings" : [{ "resource" : "consent", "version" : "1.0", "binding" : "consent" }], "type" : "text/javascript" }jsonThis can improve the legibility of your scripts, by no longer needing to pass additional information within your script function.
- file
-
string, required if
sourceis not specifiedSpecifies the file containing the source code of the script to execute. The file path must be relative to project-dir. Absolute paths are not supported.
|
In general, you should namespace variables passed into scripts with the json |
Examples
The following example script (in the mapping configuration) determines whether to include or ignore a target object in the reconciliation process based on an employeeType of true:
"validTarget" : {
"type" : "text/javascript",
"source" : "target.employeeType == 'external'"
}The following example script (in the mapping configuration) sets the __PASSWORD__ attribute to defaultpwd when IDM creates a target object:
"onCreate" : {
"type" : "text/javascript",
"source" : "target.__PASSWORD__ = 'defaultpwd'"
}Often, script files are reused in different contexts. You can pass variables to your scripts to provide these contextual details at runtime. You pass variables to the scripts that are referenced in configuration files by declaring the variable name in the script reference.
The following scheduled task configuration calls a script that triggers an email notification, but sets the sender and recipient of the email in the schedule configuration, rather than in the script itself:
{
"enabled" : true,
"type" : "cron",
"schedule" : "0 0/1 * * * ?",
"persisted" : true,
"invokeService" : "script",
"invokeContext" : {
"script" : {
"type" : "text/javascript",
"file" : "script/triggerEmailNotification.js",
"fromSender" : "admin@example.com",
"toEmail" : "user@example.com"
}
}
}Validate scripts over REST
IDM exposes a script endpoint over which scripts can be validated, by specifying the script parameters as part of the JSON payload. This functionality lets you test how a script will operate in your deployment, with complete control over the inputs and outputs. Testing scripts in this way can be useful in debugging.
In addition, the script registry service supports calls to other scripts. For example, you might have logic written in JavaScript, but also some code available in Groovy. Ordinarily, it would be challenging to interoperate between these two environments, but this script service lets you call one from the other on the IDM router.
The script endpoint supports two actions - eval and compile.
The eval action evaluates a script, by taking any actions referenced in the script, such as router calls to affect the state of an object. For JavaScript scripts, the last statement that is executed is the value produced by the script, and the expected result of the REST call.
The following REST call attempts to evaluate the autoPurgeAuditRecon.js script (provided in openidm/bin/defaults/script/audit), but provides an incorrect purge type ("purgeByNumOfRecordsToKeep" instead of "purgeByNumOfReconsToKeep"). The error is picked up in the evaluation. The example assumes that the script exists in the directory reserved for custom scripts (openidm/script):
curl \
--header "X-OpenIDM-Username: openidm-admin" \
--header "X-OpenIDM-Password: openidm-admin" \
--header "Accept-API-Version: resource=1.0" \
--header "Content-Type: application/json" \
--request POST \
--data '{
"type": "text/javascript",
"file": "script/autoPurgeAuditRecon.js",
"globals": {
"input": {
"mappings": ["%"],
"purgeType": "purgeByNumOfRecordsToKeep",
"numOfRecons": 1
}
}
}' \
"http://localhost:8080/openidm/script?_action=eval"
"Must choose to either purge by expired or number of recons to keep"
|
The variables passed into this script are namespaced with the |
The compile action compiles a script, but does not execute it. A successful compilation returns true. An unsuccessful compilation returns the reason for the failure.
The following REST call tests whether a transformation script will compile:
curl \
--header "X-OpenIDM-Username: openidm-admin" \
--header "X-OpenIDM-Password: openidm-admin" \
--header "Accept-API-Version: resource=1.0" \
--header "Content-Type: application/json" \
--request POST \
--data '{
"type":"text/javascript",
"source":"source.mail ? source.mail.toLowerCase() : null"
}' \
"http://localhost:8080/openidm/script?_action=compile"
True
If the script is not valid, the action returns an indication of the error, for example:
curl \
--header "X-OpenIDM-Username: openidm-admin" \
--header "X-OpenIDM-Password: openidm-admin" \
--header "Accept-API-Version: resource=1.0" \
--header "Content-Type: application/json" \
--request POST \
--data '{
"type":"text/javascript",
"source":"source.mail ? source.mail.toLowerCase()"
}' \
"http://localhost:8080/openidm/script?_action=compile"
{
"code": 400,
"reason": "Bad Request",
"message": "missing : in conditional expression (386...BF2#1)in 386...BF2 at line number 1 at column number 39"
}
Create custom endpoints to launch scripts
Custom endpoints let you run arbitrary scripts through the REST API.
A custom endpoint configuration includes an inline script, or script file reference, in either JavaScript or Groovy. The script provides the endpoint functionality.
A sample custom endpoint configuration is provided in the openidm/samples/example-configurations/custom-endpoint
directory. The sample includes three files:
- conf/endpoint-echo.json
-
Provides the configuration for the endpoint.
- script/echo.js
-
Provides the endpoint functionality in JavaScript.
- script/echo.groovy
-
Provides the endpoint functionality in Groovy.
|
This sample endpoint is described in detail in the sample: Create a custom endpoint. |
Custom endpoint configuration
A custom endpoint configuration has the following structure:
{
"context" : "context path",
"type" : "script language",
"source" : "script source" | "file" : "script file",
"apiDescription" : "API descriptor object"
}context-
string, optional
The root URL path for the endpoint, in other words, the route to the endpoint. An endpoint with the context
endpoint/testis addressable over REST at the URLhttp://localhost:8080/openidm/endpoint/testor by using a script such asopenidm.read("endpoint/test").Endpoint contexts support wild cards, as shown in the preceding example. The
endpoint/linkedview/*route matches the following patterns:endpoint/linkedView/managed/user/bjensen endpoint/linkedView/system/ldap/account/bjensen endpoint/linkedView/ endpoint/linkedView
The
contextparameter is not mandatory in the endpoint configuration file. If you do not include acontext, the route to the endpoint is identified by the name of the file. For example, in the sample endpoint configuration provided inopenidm/samples/example-configurations/custom-endpoint/conf/endpoint-echo.json, the route to the endpoint isendpoint/echo. type-
string, required
The script type.
IDM supports
"text/javascript"and"groovy". fileorsource-
The path to the script file, or the script itself, inline.
For example:
"file" : "workflow/gettasksview.js"or
"source" : "require('linkedView').fetch(request.resourcePath);" apiDescription-
JSON object, optional
Describes the custom endpoint and includes its documentation in the REST API Explorer.
|
You must set authorization for any custom endpoints that you add, for example, by restricting the methods to the appropriate roles. For more information, refer to Authorization and Roles. |
Custom endpoint scripts
The custom endpoint script files in the samples/example-configurations/custom-endpoint/script
directory demonstrate all the HTTP operations that can be called by a script. Each HTTP operation is associated with a method (create, read, update, delete, patch, action, or query). Requests sent to the custom endpoint return a list of the variables available to each method.
All scripts are invoked with a global request variable in their scope. This request structure carries all the information about the request.
|
Read requests on custom endpoints must not modify the state of the resource, either on the client or the server, as this can make them susceptible to CSRF exploits. The standard READ endpoints are safe from Cross Site Request Forgery (CSRF) exploits because they are inherently read-only. That is consistent with the Guidelines for Implementation of REST, from the US National Security Agency, as "… CSRF protections need only be applied to endpoints that will modify information in some way." |
Custom endpoint scripts must return a JSON object. The structure of the return object depends on the method in the request.
The following example shows the create method in the echo.js file:
if (request.method === "create") {
return {
method: "create",
resourceName: request.resourcePath,
newResourceId: request.newResourceId,
parameters: request.additionalParameters,
content: request.content,
context: context.current
}
}The following example shows the query method in the echo.groovy file:
else if (request instanceof QueryRequest) {
// query results must be returned as a list of maps
return [
[
method: "query",
resourceName: request.resourcePath,
pagedResultsCookie: request.pagedResultsCookie,
pagedResultsOffset: request.pagedResultsOffset,
pageSize: request.pageSize,
queryId: request.queryId,
queryFilter: request.queryFilter.toString(),
parameters: request.additionalParameters,
context: context.toJsonValue().getObject()
]
]
}Depending on the method, the variables available to the script can include the following:
resourceName-
The name of the resource, without the
endpoint/prefix, such asecho. newResourceId-
The identifier of the new object, available as the results of a
createrequest. revision-
The revision of the object.
parameters-
Any additional parameters provided in the request. The sample code returns request parameters from an HTTP GET with
?param=x, as"parameters":{"param":"x"}. content-
Content based on the latest revision of the object, using
getObject. context-
The context of the request, including headers and security. For more information, refer to Request context chain.
- Paging parameters
-
The
pagedResultsCookie,pagedResultsOffset, andpageSizeparameters are specific toquerymethods. For more information refer to Page Query Results. - Query parameters
-
The
queryIdandqueryFilterparameters are specific toquerymethods. For more information refer to Construct Queries.
Script exceptions
Some custom endpoint scripts require exception-handling logic. To return meaningful messages in REST responses and in logs, you must comply with the language-specific method of throwing errors.
A script written in JavaScript should comply with the following exception format:
throw {
"code": 400, // any valid HTTP error code
"message": "custom error message",
"detail" : {
"var": parameter1,
"complexDetailObject" : [
"detail1",
"detail2"
]
}
}Any exceptions will include the specified HTTP error code, the corresponding HTTP error message, such as Bad Request, a custom error message that can help you diagnose the error, and any additional detail that you think might be helpful.
A script written in Groovy should comply with the following exception format:
import org.forgerock.json.resource.ResourceException
import org.forgerock.json.JsonValue
throw new ResourceException(404, "Your error message").setDetail(new JsonValue([
"var": "parameter1",
"complexDetailObject" : [
"detail1",
"detail2"
]
]))Write an API descriptor for a custom endpoint
Most IDM endpoints are described in the REST API Explorer. Documentation is not generated automatically for custom endpoints.
To generate the documentation for your custom endpoint in the API Explorer, add an apiDescription object to your custom endpoint configuration file. The apiDescription object includes the following properties:
title-
The endpoint name, which expresses its purpose. For example,
Audit, orAuthentication. description-
A description of the endpoint.
mvccSupported-
Boolean,
trueorfalse.Indicates whether object versioning is supported. If you want to use
If-None-MatchorIf-Matchheaders in read, delete, and patch requests, you must set"mvccSupported" : true. - Operations
-
An object that describes each operation supported on that endpoint (
create,read,update,delete,patch,actions, andqueries). resourceSchema-
The schema for the objects at this endpoint.
To refer to examples of the API descriptors included in IDM, log in to the admin UI then point your browser to http://localhost:8080/openidm?_crestapi.
Compare the descriptors at that URL with what you refer to in the API Explorer.
In addition, the sample configuration file (openidm/samples/example-configurations/custom-endpoint/conf/endpoint-echo.json) shows how API descriptors must be constructed:
Sample API Descriptor Object
{
"apiDescription" : {
"title" : "Echo",
"description" : "Service that echo's your HTTP requests.",
"mvccSupported" : false,
"create" : {
"description" : "Echo a CREATE request.",
"mode" : "ID_FROM_SERVER",
"singleton" : false
},
"read" : { "description" : "Echo a READ request." },
"update" : { "description" : "Echo an UPDATE request." },
"delete" : { "description" : "Echo a DELETE request." },
"patch" : {
"description" : "Echo a PATCH request.",
"operations" : [ "ADD", "REMOVE", "REPLACE", "INCREMENT", "COPY", "MOVE", "TRANSFORM" ]
},
"actions" : [
{
"description" : "Echo an ACTION request.",
"name" : "echo",
"request" : { "type" : "object" },
"response" : {
"title" : "Echo action response",
"type" : "object",
"properties" : {
"method" : {
"type" : "string",
"enum" : [ "action" ]
},
"action" : { "type" : "string" },
"content" : { "type" : "object" },
"parameters" : { "type" : "object" },
"context" : { "type" : "object" }
}
}
}
],
"queries" : [
{
"description" : "Echo a query-filter request.",
"type" : "FILTER",
"queryableFields" : [ "*" ]
},
{
"description" : "Echo a query-all request.",
"type" : "ID",
"queryId" : "query-all"
},
{
"description" : "Echo a query-all-ids request.",
"type" : "ID",
"queryId" : "query-all-ids"
}
],
"resourceSchema" : {
"title" : "Echo resource",
"type" : "object",
"properties" : {
"method" : {
"title" : "CREST method",
"type" : "string"
},
"resourceName" : { "type" : "string" },
"parameters" : { "type" : "object" },
"context" : { "type" : "object" }
}
}
}
}This object generates API documentation in the API explorer that looks like this:
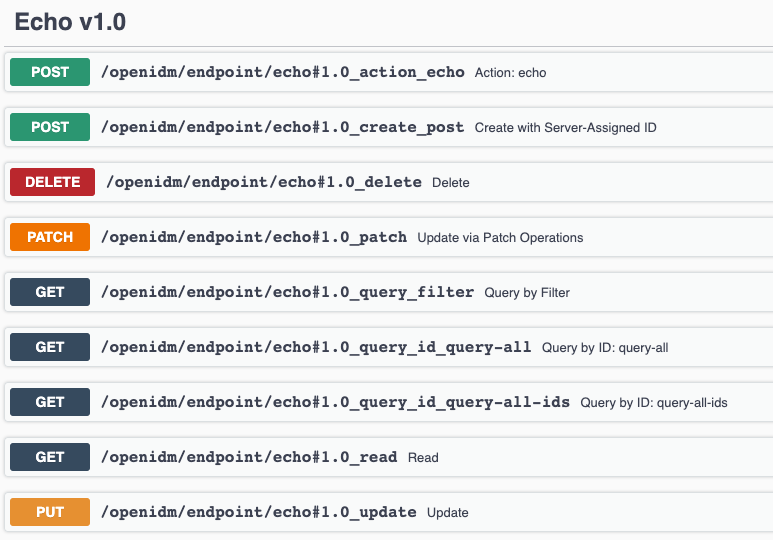
Register custom scripted actions
You can register custom scripts that initiate some arbitrary action on a managed object endpoint. You can declare any number of actions in your managed object schema and associate those actions with a script.
The return value of a custom scripted action is ignored. The managed object is returned as the response of the scripted action, whether that object has been updated by the script or not.
Custom scripted actions have access to the following variables:
-
context -
request -
resourcePath -
object
Example scenario
In this scenario, you want your managed users to have the option to receive update notifications. You can define an action that toggles the value of a specific property on the user object.
-
Add an
updatesproperty to the managed object configuration:"properties": { ... "updates": { "title": "Automatic Updates", "viewable": true, "type": "boolean", "searchable": true, "userEditable": true }, ... }json -
Add a
toggleUpdatesaction to the managed user object definition:{ "objects" : [ { "name" : "user", "onCreate" : { ... }, ... "actions" : { "toggleUpdates" : { "type" : "text/javascript", "source" : "openidm.patch(resourcePath, null, [{ 'operation' : 'replace', 'field' : '/updates', 'value' : !object.updates }])" } }, ... } ] }jsonThe toggleUpdatesaction calls a script that changes the value of the user’supdatesproperty. -
To call the script, specify the ID of the action in a POST request on the user object:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "http://localhost:8080/openidm/managed/user/ID?_action=toggleUpdates"
You can now test the functionality.
-
Create a managed user,
bjensen, with anupdatesproperty set totrue:curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header "Accept-API-Version: resource=1.0" \ --header "Content-Type: application/json" \ --request POST \ --data '{ "userName":"bjensen", "sn":"Jensen", "givenName":"Barbara", "mail":"bjensen@example.com", "telephoneNumber":"5556787", "description":"Created by OpenIDM REST.", "updates": true, "password":"Passw0rd" }' \ "http://localhost:8080/openidm/managed/user?_action=create" { "_id": "9dce06d4-2fc1-4830-a92b-bd35c2f6bcbb", "_rev": "0000000050c62938", "userName": "bjensen", "sn": "Jensen", "givenName": "Barbara", "mail": "bjensen@example.com", "telephoneNumber": "5556787", "description": "Created by OpenIDM REST.", "updates": true, "accountStatus": "active", "effectiveRoles": [], "effectiveAssignments": [] } -
Run the
toggleUpdatesaction onbjensen:curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "http://localhost:8080/openidm/managed/user/9dce06d4-2fc1-4830-a92b-bd35c2f6bcbb?_action=toggleUpdates" { "_id": "9dce06d4-2fc1-4830-a92b-bd35c2f6bcbb", "_rev": "00000000a92657c7", "userName": "bjensen", "sn": "Jensen", "givenName": "Barbara", "mail": "bjensen@example.com", "telephoneNumber": "5556787", "description": "Created by OpenIDM REST.", "updates": false, "accountStatus": "active", "effectiveRoles": [], "effectiveAssignments": [] }Note in the command output that this action has set bjensen’s updatesproperty tofalse.
Request context chain
The context chain of any request is established as follows:
-
The request starts with a root context, associated with a specific context ID.
-
The root context is wrapped in the security context that includes the authentication and authorization detail for the request.
-
The security context is further wrapped by the HTTP context, with the target URI. The HTTP context is associated with the normal parameters of the request, including a user agent, authorization token, and method.
-
The HTTP context is wrapped by one or more server/router context(s), with an endpoint URI. The request can have several layers of server and router contexts.
Script triggers
| For more information about the variables available to scripts, refer to Script variables. |
Scripts can be triggered in different places, and by different events. The following list indicates the configuration files in which scripts can be referenced, the events upon which the scripts can be triggered, and the actual scripts that can be triggered on each of these files.
- Scripts called in mappings
-
- Triggered by situation
-
onCreate, onUpdate, onDelete, onLink, onUnlink
- Object filter
-
validSource, validTarget
- Triggered when correlating objects
-
correlationQuery, correlationScript
- Triggered on any reconciliation
-
result
- Scripts inside properties
-
condition, transform
sync.jsonsupports only one script per hook. If multiple scripts are defined for the same hook, only the last one is kept. - Scripts inside policies
-
condition
Within a synchronization policy, you can use a
conditionscript to apply different policies based on the link type, for example:"condition" : { "type" : "text/javascript", "source" : "linkQualifier == \"user\"" }json
- Scripts called in the managed object configuration
-
onCreate, onRead, onUpdate, onDelete, onValidate, onRetrieve, onStore, onSync, postCreate, postUpdate, and postDelete
The managed object configuration supports only one script per hook. If multiple scripts are defined for the same hook, only the last one is kept.
- Scripts called in the router configuration
-
onRequest, onResponse, onFailure
The router configuration supports multiple scripts per hook.
Script triggers defined in the managed object configuration
For information about how managed objects are handled and the available script triggers, refer to Managed objects reference.
Managed object configuration object
| Trigger | Variable |
|---|---|
|
|
Returns JSON object |
|
Returns JSON object. |
|
Returns JSON object. |
|
Returns JSON object |
|
Returns JSON object |
|
Property object
| Trigger | Variable |
|---|---|
Returns JSON object |
|
Returns JSON object |
|
Script triggers defined in mappings
For information about how managed objects in mappings are handled, and the script triggers available, refer to Object-Mapping Objects.
Object-mapping object
| Trigger | Variable |
|---|---|
Returns JSON object |
|
Returns JSON object |
|
Returns JSON object |
|
Returns JSON object |
|
Returns JSON object |
|
Returns JSON object |
|
Returns JSON object of reconciliation results |
|
Returns boolean |
|
Returns boolean |
|
Property object
| Trigger | Variable |
|---|---|
Returns boolean |
|
Returns JSON object |
|
Policy object
| Trigger | Variable |
|---|---|
Returns string OR JSON object |
|
Returns JSON object |
|
Script triggers defined in the router configuration
| Trigger | Variable |
|---|---|
|
exception |
|
request |
|
response |
The augmentSecurityContext trigger
The augmentSecurityContext trigger, defined in the authentication configuration, can reference a script that is executed after successful authentication. Such scripts can populate the security context of the authenticated user. If the authenticated user is not found in the resource specified by queryOnResource, the augmentSecurityContext can provide the required authorization map.
Such scripts have access to the following bindings:
-
security- includes theauthenticationIdand theauthorizationkey, which includes themoduleId.The main purpose of an
augmentSecurityContextscript is to modify theauthorizationmap that is part of thissecuritybinding. The authentication module determines the value of theauthenticationId, and IDM attempts to populate theauthorizationmap with the details that it finds, related to thatauthenticationIdvalue. These details include the following:-
security.authorization.component- the resource that contains the account (this will always will be the same as the value ofqueryOnResourceby default). -
security.authorization.id- the internal_idvalue that is associated with the account. -
security.authorization.roles- any roles that were determined, either from reading theuserRolesproperty of the account or from calculation. -
security.authorization.moduleId- the authentication module responsible for performing the original authentication.
You can use the
augmentSecurityContextscript to change any of theseauthorizationvalues. The script can also add new values to theauthorizationmap, which will be available for the lifetime of the session. -
-
properties- corresponds to thepropertiesmap of the related authentication module. -
httpRequest- a reference to theRequestobject that was responsible for handling the incoming HTTP request.This binding is useful to the augment script because it has access to all of the raw details from the HTTP request, such as the headers. The following code snippet shows how you can access a header using the
httpRequestbinding. This example accesses theauthTokenrequest header:httpRequest.getHeaders().getFirst('authToken').toString()
Script variables
| For more information about the variables available in script triggers, refer to Script triggers. |
The variables available to a script depend on several factors:
-
The trigger that launches the script.
-
The configuration file in which that trigger is defined.
-
The object type:
-
For objects defined in the managed object configuration, the object type is either a managed object, or a managed object property.
-
For objects defined in the mapping configuration, the object can be an object-mapping object, a property object, or a policy object. For more information, refer to Policy Objects).
-
The following subtopics list the variables available to scripts, based on the configuration file in which the trigger is defined.
Variables available to scripts in custom endpoints
All custom endpoint scripts have a request variable in their scope, which is a JSON object containing all information about the request. The parameters found in this object vary depending on the request method. The request may include headers, credentials, and the desired action. The request normally also includes the endpoint as well as the payload to be processed.
For more details about writing custom endpoint scripts, refer to Custom Endpoint Scripts.
| Variable | Variable Parameters |
|---|---|
|
|
Variables available to role assignment scripts
The optional onAssignment and onUnassignment event scripts specify what should happen to attributes that are affected by role assignments when those assignments are applied to a user, or removed from a user.
These scripts have access to the following variables:
-
sourceObject -
targetObject -
existingTargetObject -
linkQualifier
The standard assignment scripts, replaceTarget.js, mergeWithTarget.js, removeFromTarget.js, and noOp.js have access to all the variables in the previous list, as well as the following:
-
attributeName -
attributeValue -
attributesInfo
|
Role assignment scripts must always return |
The identityServer variable
IDM provides an additional variable, named identityServer, to scripts. You can use this variable in several ways. The ScriptRegistryService, described in Validate scripts over REST, binds this variable to:
-
getPropertyRetrieves property information from system configuration files. Takes up to three parameters:
-
The name of the property you are requesting.
-
(Optional) The default result to return if the property wasn’t set.
-
(Optional) Boolean to determine whether or not to use property substitution when getting the property.
For more information about property substitution, refer to Property value substitution.
Returns the first property found following the same order of precedence IDM uses to check for properties: environment variables,
system.properties,boot.properties, and then other configuration files.For more information, refer to Server configuration.
For example, you can retrieve the value of the
openidm.config.crypto.aliasproperty with the following code:alias = identityServer.getProperty("openidm.config.crypto.alias", "true", true);
-
-
getInstallLocationRetrieves the IDM installation path, such as
/path/to/openidm. May be superseded by an absolute path. -
getProjectLocationRetrieves the directory used when you started IDM. That directory includes configuration and script files for your project.
For more information on the project location, refer to Startup configuration.
-
getWorkingLocationRetrieves the directory associated with database cache and audit logs. You can find
db/andaudit/subdirectories there.For more information on the working location, refer to Startup configuration.
Router configuration
The router service provides the uniform interface to all IDM objects: managed objects, system objects, configuration objects, and so on.
The router configuration contains an array of Filter objects:
{
"filters": [ filter object, ... ]
}Filter objects
The required filters array defines a list of filters to be processed on each router request. Filters are processed in the order in which they are specified in this array, and have the following configuration:
{
"pattern": string,
"methods": [ string, ... ],
"condition": script object,
"onRequest": script object,
"onResponse": script object,
"onFailure": script object
}- pattern
-
string, optional
Specifies a regular expression pattern matching the JSON pointer of the object to trigger scripts. If not specified, all identifiers (including
null) match. Pattern matching is done on the resource name, rather than on individual objects. - methods
-
array of strings, optional
One or more methods for which the script(s) should be triggered. Supported methods are:
"create","read","update","delete","patch","query","action". If not specified, all methods are matched. - condition
-
script object, optional
Specifies a script that is called first to determine if the script should be triggered. If the condition yields
"true", the other script(s) are executed. If no condition is specified, the script(s) are called unconditionally. - onRequest
-
script object, optional
Specifies a script to execute before the request is dispatched to the resource. If the script throws an exception, the method is not performed, and a client error response is provided.
- onResponse
-
script object, optional
Specifies a script to execute after the request is successfully dispatched to the resource and a response is returned. Throwing an exception from this script does not undo the method already performed.
- onFailure
-
script object, optional
Specifies a script to execute if the request resulted in an exception being thrown. Throwing an exception from this script does not undo the method already performed.
Pattern matching in the router configuration
Pattern matching can minimize overhead in the router service. The default router configuration includes instances of the pattern filter object, that limit script requests to specified methods and endpoints.
Based on the following code snippet, the router service would trigger the policyFilter.js
script for CREATE and UPDATE calls to managed and internal objects:
{
"pattern" : "^(managed|internal)($|(/.+))",
"onRequest" : {
"type" : "text/javascript",
"source" : "require('policyFilter').runFilter()"
},
"methods" : [
"create",
"update"
]
}Without this pattern, IDM would apply the policy filter to additional objects, such as the audit service, which could affect performance.
Script execution sequence
All onRequest and onResponse scripts are executed in sequence. First, the onRequest scripts are executed from the top down, then the onResponse scripts are executed from the bottom up.
client -> filter 1 onRequest -> filter 2 onRequest -> resource client <- filter 1 onResponse <- filter 2 onResponse <- resource
The following sample router configuration shows the order in which the scripts would be executed:
{
"filters" : [
{
"onRequest" : {
"type" : "text/javascript",
"source" : "require('router-authz').testAccess()"
}
},
{
"pattern" : "^managed/user",
"methods" : [
"read"
],
"onRequest" : {
"type" : "text/javascript",
"source" : "console.log('requestFilter 1');"
}
},
{
"pattern" : "^managed/user",
"methods" : [
"read"
],
"onResponse" : {
"type" : "text/javascript",
"source" : "console.log('responseFilter 1');"
}
},
{
"pattern" : "^managed/user",
"methods" : [
"read"
],
"onRequest" : {
"type" : "text/javascript",
"source" : "console.log('requestFilter 2');"
}
},
{
"pattern" : "^managed/user",
"methods" : [
"read"
],
"onResponse" : {
"type" : "text/javascript",
"source" : "console.log('responseFilter 2');"
}
}
]
}This configuration would produce a log as follows:
requestFilter 1
requestFilter 2
responseFilter 2
responseFilter 1Example Filter Configuration
This example executes a script after a managed user object is created or updated:
{
"filters": [
{
"pattern": "^managed/user",
"methods": [
"create",
"update"
],
"onResponse": {
"type": "text/javascript",
"file": "scripts/afterUpdateUser.js"
}
}
]
}Script scope
Scripts are provided with the following scope:
{
"openidm": openidm-functions object,
"request": resource-request object,
"response": resource-response object,
"exception": exception object
}- openidm
-
Provides access to IDM resources.
- request
-
resource-request object
The resource-request context, which has one or more parent contexts. Provided in the scope of all scripts. For more information about the request context, refer to Request context chain.
- response
-
resource-response object
The response to the resource-request. Only provided in the scope of the
"onResponse"script. - exception
-
exception object
The exception value that was thrown as a result of processing the request. Only provided in the scope of the
"onFailure"script. An exception object is defined as:{ "code": integer, "reason": string, "message": string, "detail": string }json - code
-
integer
The numeric HTTP code of the exception.
- reason
-
string
The short reason phrase of the exception.
- message
-
string
A brief message describing the exception.
- detail
-
(optional), string
A detailed description of the exception, in structured JSON format, suitable for programmatic evaluation.
Scripting function reference
|
If you need to request specific resource versions, refer to REST API versioning. |
Functions (access to managed objects, system objects, and configuration objects) within IDM are accessible to scripts via the openidm object, which is included in the top-level scope provided to each script.
|
Most of the following function examples are in JavaScript. To use the functions in Groovy scripts, make adjustments as necessary. For example, you need to pass parameters using square brackets (not curly braces): groovy |
The script engine supports the following functions:
openidm.create(resourceName, newResourceId, content, params, fields)
This function creates a new resource object.
- Parameters
-
- resourceName
-
string
The container in which the object will be created, for example,
managed/user. - newResourceId
-
string
The identifier of the object to be created, if the client is supplying the ID. If the server should generate the ID, pass null here.
- content
-
JSON object
The content of the object to be created.
- params
-
JSON object (optional)
Additional parameters that are passed to the create request.
- fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire new object is returned.
- Returns
-
The created resource object.
- Throws
-
An exception is thrown if the object could not be created.
- Example
-
openidm.create("managed/user", ID, JSON object);javascript
openidm.patch(resourceName, rev, value, params, fields)
This function performs a partial modification of a managed or system object. Unlike the update function, only the modified attributes are provided, not the entire object.
- Parameters
-
- resourceName
-
string
The full path to the object being updated, including the ID.
- rev
-
string
The revision of the object to be updated. Use
nullif the object is not subject to revision control, or if you want to skip the revision check and update the object, regardless of the revision. - value
-
An array of one or more JSON objects
The value of the modifications to be applied to the object. The patch set includes the operation type, the field to be changed, and the new values. A PATCH request can
add,remove,replace, orincrementan attribute value.A
removeoperation removes a property if the value of that property equals the specified value, or if no value is specified in the request. The following examplevalueremoves themarital_statusproperty from the object, if the value of that property issingle:[ { "operation": "remove", "field": "marital_status", "value": "single" } ]jsonFor fields whose value is an array, it’s not necessary to know the position of the value in the array, as long as you specify the full object. If the full object is found in the array, that value is removed. The following example removes user adonnelly from bjensen’s
reports:{ "operation": "remove", "field": "/manager", "value": { "_ref": "managed/user/adonnelly", "_refResourceCollection": "managed/user", "_refResourceId": "adonnelly", "_refProperties": { "_id": "ed6620e4-98ba-410c-abc0-e06dc1be7aa7", "_rev": "000000008815942b" } } }jsonIf an invalid value is specified (that is a value that does not exist for that property in the current object) the patch request is silently ignored.
A
replaceoperation replaces an existing value, or adds a value if no value exists.
- params
-
JSON object (optional)
Additional parameters that are passed to the patch request.
- fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire new object is returned. - Returns
-
The modified resource object.
- Throws
-
An exception is thrown if the object could not be updated.
- Examples
-
Patching an object to add a value to an array:
openidm.patch("managed/role/" + role._id, null, [{"operation":"add", "field":"/members/-", "value": {"_ref":"managed/user/" + user._id}}]);javascriptPatching an object to remove an existing property:
openidm.patch("managed/user/" + user._id, null, [{"operation":"remove", "field":"marital_status", "value":"single"}]);javascriptPatching an object to replace a field value:
openidm.patch("managed/user/" + user._id, null, [{"operation":"replace", "field":"/password", "value":"Passw0rd"}]);javascriptPatching an object to increment an integer value:
openidm.patch("managed/user/" + user._id, null, [{"operation":"increment","field":"/age","value":1}]);javascript
openidm.read(resourceName, params, fields)
This function reads and returns a resource object.
- Parameters
-
- resourceName
-
string
The full path to the object to be read, including the ID.
- params
-
JSON object (optional)
The parameters that are passed to the read request. Generally, no additional parameters are passed to a read request, but this might differ, depending on the request. If you need to specify a list of
fieldsas a third parameter, and you have no additionalparamsto pass, you must passnullhere. Otherwise, you simply omit both parameters. - fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire object is returned.
- Returns
-
The resource object, or
nullif not found. - Example
-
openidm.read("managed/user/"+userId, null, ["*", "manager"]);javascript
openidm.update(resourceName, rev, value, params, fields)
This function updates an entire resource object.
- Parameters
-
- id
-
string
The complete path to the object to be updated, including its ID.
- rev
-
string
The revision of the object to be updated. Use
nullif the object is not subject to revision control, or if you want to skip the revision check and update the object, regardless of the revision. - value
-
object
The complete replacement object.
- params
-
JSON object (optional)
The parameters that are passed to the update request.
- fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire object is returned.
- Returns
-
The modified resource object.
- Throws
-
An exception is thrown if the object could not be updated.
- Example
-
In this example, the managed user entry is read (with an
openidm.read, the user entry that has been read is updated with a new description, and the entire updated object is replaced with the new value.var user_read = openidm.read('managed/user/' + source._id); user_read['description'] = 'The entry has been updated'; openidm.update('managed/user/' + source._id, null, user_read);javascript
openidm.delete(resourceName, rev, params, fields)
This function deletes a resource object.
- Parameters
-
- resourceName
-
string
The complete path to the to be deleted, including its ID.
- rev
-
string
The revision of the object to be deleted. Use
nullif the object is not subject to revision control, or if you want to skip the revision check and delete the object, regardless of the revision. - params
-
JSON object (optional)
The parameters that are passed to the delete request.
- fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire object is returned.
- Returns
-
Returns the deleted object if successful.
- Throws
-
An exception is thrown if the object could not be deleted.
- Example
-
openidm.delete('managed/user/'+ user._id, user._rev);javascript
openidm.query(resourceName, params, fields)
This function performs a query on the specified resource object. For more information, refer to Construct Queries.
- Parameters
-
- resourceName
-
string
The resource object on which the query should be performed, for example,
"managed/user", or"system/ldap/account". - params
-
JSON object
The parameters that are passed to the query (
_queryFilter, or_queryId). Additional parameters passed to the query will differ, depending on the query.Certain common parameters can be passed to the query to restrict the query results. The following sample query passes paging parameters and sort keys to the query.
reconAudit = openidm.query("audit/recon", { "_queryFilter": queryFilter, "_pageSize": limit, "_pagedResultsOffset": offset, "_pagedResultsCookie": string, "_sortKeys": "-timestamp" });javascriptFor more information about
_queryFiltersyntax, refer to Common Filter Expressions. For more information about paging, refer to Page Query Results. - fields
-
list
A list of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. The following example returns only theuserNameand_idfields:openidm.query("managed/user", { "_queryFilter": "/userName sw \"user.1\""}, ["userName", "_id"]);javascriptThis parameter is particularly useful in enabling you to return the response from a query without including intermediary code to massage it into the right format.
Fields are specified as JSON pointers.
- Returns
-
The result of the query. A query result includes the following parameters:
- query-time-ms
-
(For JDBC repositories only) the time, in milliseconds, that IDM took to process the query.
- result
-
The list of entries retrieved by the query. The result includes the properties that were requested in the query.
The following example shows the result of a custom query that requests the ID, user name, and email address of all managed users in the repository.
{ "result": [ { "_id": "9dce06d4-2fc1-4830-a92b-bd35c2f6bcbb", "_rev": "00000000a059dc9f", "userName": "bjensen", "mail": "bjensen@example.com" }, { "_id": "42f8a60e-2019-4110-a10d-7231c3578e2b", "_rev": "00000000d84ade1c", "userName": "scarter", "mail": "scarter@example.com" } ], "resultCount": 2, "pagedResultsCookie": null, "totalPagedResultsPolicy": "NONE", "totalPagedResults": -1, "remainingPagedResults": -1 }json
- Throws
-
An exception is thrown if the given query could not be processed.
- Examples
-
The following sample query uses a
_queryFilterto query the managed user repository:openidm.query("managed/user", {'_queryFilter': userIdPropertyName + ' eq "' + security.authenticationId + '"'});javascriptThe following sample query references the
for-userNamequery, defined in the repository configuration, to query the managed user repository:openidm.query("managed/user", {"_queryId": "for-userName", "uid": request.additionalParameters.uid });javascript
openidm.action(resource, actionName, content, params, fields)
This function performs an action on the specified resource object. The resource and actionName are required. All other parameters are optional.
- Parameters
-
- resource
-
string
The resource that the function acts upon, for example,
managed/user. - actionName
-
string
The action to execute. Actions are used to represent functionality that is not covered by the standard methods for a resource (create, read, update, delete, patch, or query). In general, you should not use the
openidm.actionfunction for create, read, update, patch, delete or query operations. Instead, use the corresponding function specific to the operation (for example,openidm.create).Using the operation-specific functions lets you benefit from the well-defined REST API, which follows the same pattern as all other standard resources in the system. Using the REST API enhances usability for your own API, and enforces the established patterns.
IDM-defined resources support a fixed set of actions. For user-defined resources (scriptable endpoints) you can implement whatever actions you require.
- Supported Actions Per Resource
-
The following list outlines the supported actions for each resource or endpoint. The actions listed here are also supported over the REST interface.
- Actions supported on the
authenticationendpoint (authentication/*) -
reauthenticate
- Actions supported on the configuration resource (
config/) -
No action parameter applies.
- Actions supported on custom endpoints
-
Custom endpoints enable you to run arbitrary scripts through the REST URI, and are routed at
endpoint/name, where name generally describes the purpose of the endpoint. For more information on custom endpoints, refer to Create custom endpoints to launch scripts. You can implement whatever actions you require on a custom endpoint. IDM uses custom endpoints in its workflow implementation. Those endpoints, and their actions are as follows:endpoint/getprocessforuser-create, complete
endpoint/gettasksview-create, complete - Actions supported on the
externalendpoint -
-
external/email-send, for example:{ emailParams = { "from" : 'admin@example.com', "to" : user.mail, "subject" : 'Password expiry notification', "type" : 'text/plain', "body" : 'Your password will expire soon. Please change it!' } openidm.action("external/email", "send", emailParams); }javascript -
external/email-sendTemplate, for example:{ emailParams = { "templateName" : "welcome", "to" : user.mail, "cc" : "ccUser1@example.com,ccUser2@example.com", "bcc" : "bigBoss@example.com" } openidm.action("external/email", "sendTemplate", emailParams); }javascript -
external/rest-call, for example:openidm.action("external/rest", "call", params);javascript
-
- Actions supported on the
infoendpoint (info/*) -
No action parameter applies.
- Actions supported on managed resources (
managed/*) -
patch, triggerSyncCheck
- Actions supported on the policy resource (
policy) -
validateObject, validateProperty
For example:
openidm.action("policy/" + fullResourcePath, "validateObject", request.content, { "external" : "true" });javascript - Actions supported on the reconciliation resource (
recon) -
recon, reconById, cancel
For example:
openidm.action("recon/_id", "cancel", content, params);javascriptA cancel action requires the entire reconciliation resource path (_id). - Actions supported on the repository (
repo) -
command
For example:
var r, command = { "commandId": "purge-by-recon-number-of", "numberOf": numOfRecons, "includeMapping": includeMapping, "excludeMapping": excludeMapping }; r = openidm.action("repo/audit/recon", "command", {}, command);javascript - Actions supported on the script resource (
script) -
eval
For example:
openidm.action("script", "eval", getConfig(scriptConfig), {});javascript - Actions supported on the synchronization resource (
sync) -
getLinkedResources, notifyCreate, notifyDelete, notifyUpdate, performAction
For example:
openidm.action('sync', 'performAction', content, params);javascript - Actions supported on system resources (
system/*) -
availableConnectors, createCoreConfig, createFullConfig, test, testConfig, liveSync, authenticate, script
For example:
openidm.action("system/ldap/account", "authenticate", {"username" : "bjensen", "password" : "Passw0rd"});javascript - Actions supported on the task scanner resource (
taskscanner) -
execute, cancel
- Actions supported on the workflow resource (
workflow/*) -
On
workflow/processdefinitioncreate, completeOn
workflow/processinstancecreate, completeFor example:
var params = { "_key":"contractorOnboarding" }; openidm.action('workflow/processinstance', 'create', params);javascriptOn
workflow/taskinstanceclaim, create, completeFor example:
var params = { "userId":"manager1" }; openidm.action('workflow/taskinstance/15', 'claim', params);javascript
- Actions supported on the
- content
-
object
Content given to the action for processing.
- params
-
object (optional)
Additional parameters passed to the script. The
paramsobject must be a set of simple key:value pairs, and cannot include complex values. The parameters must map directly to URL variables, which take the formname1=val1&name2=val2&…. - fields
-
JSON array (optional)
An array of the fields that should be returned in the result. The list of fields can include wild cards, such as
*or*_ref. If no fields are specified, the entire object is returned.
- Returns
-
The result of the action may be
null. - Throws
-
If the action cannot be executed, an object containing an
errorproperty is returned.
openidm.encrypt(value, cipher, alias)
This function encrypts a value.
- Parameters
-
- value
-
any
The value to be encrypted.
- cipher
-
string
The cipher with which to encrypt the value, using the form "algorithm/mode/padding" or just "algorithm". Example:
AES/CBC/PKCS5Padding. - alias
-
string
The key alias in the keystore, such as
openidm-sym-default(deprecated) or a purpose defined in thesecrets.jsonfile, such asidm.password.encryption.
- Returns
-
The value, encrypted with the specified cipher and key.
- Throws
-
An exception is thrown if the object could not be encrypted.
openidm.decrypt(value)
This function decrypts a value.
- Parameters
-
- value
-
object
The value to be decrypted.
- Returns
-
A deep copy of the value, with any encrypted value decrypted.
- Throws
-
An exception is thrown if the object could not be decrypted for any reason. An error is thrown if the value is passed in as a string - it must be passed in an object.
openidm.isEncrypted(object)
This function determines if a value is encrypted.
- Parameters
-
- object to check
-
any
The object whose value should be checked to determine if it is encrypted.
- Returns
-
Boolean,
trueif the value is encrypted, andfalseif it is not encrypted. - Throws
-
An exception is thrown if the server is unable to detect whether the value is encrypted, for any reason.
openidm.hash(value, algorithm, options)
This function calculates a value using a salted hash algorithm.
| Algorithm | Config Property and Description | ||
|---|---|---|---|
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
- Parameters
-
- value
-
any
The value to be hashed.
- algorithm
-
string (optional)
The hashing algorithm. Example:
SHA-512.If no algorithm is provided, a
nullvalue must be passed, and the algorithm defaults to SHA-256. - options
-
For Groovy, Map or JSON value (optional)
For JavaScript, JSON object (optional)
Configuration properties for the selected algorithm.
- Returns
-
The value, calculated with the specified hash algorithm.
- Throws
-
An exception is thrown if the object could not be hashed for any reason.
- Examples
-
- Groovy (Map)
-
openidm.hash(\"dummy\", \"BCRYPT\", [\"cost\": 10]);groovy - Groovy (JSON value)
-
JsonValue v = new JsonValue( [\"cost\": 10]); return openidm.hash(\"dummy\", \"BCRYPT\", v);groovy - JavaScript
-
openidm.hash(\"dummy\", \"BCRYPT\", {\"cost\": 10})javascript
openidm.isHashed(value)
This function detects whether a value has been calculated with a salted hash algorithm.
- Parameters
-
- value
-
any
The value to be reviewed.
- Returns
-
Boolean,
trueif the value is hashed, andfalseotherwise. - Throws
-
An exception is thrown if the server is unable to detect whether the value is hashed, for any reason.
openidm.matches(string, value)
This function detects whether a string, when hashed, matches an existing hashed value.
- Parameters
-
- string
-
any
A string to be hashed.
- value
-
any
A hashed value to compare to the string.
- Returns
-
Boolean,
trueif the hash of the string matches the hashed value, andfalseotherwise. - Throws
-
An exception is thrown if the string could not be hashed.
|
These functions can also have a vanity binding to make them more descriptive, such as See Call a script from the IDM configuration for more information about |
Log functions
IDM also provides a logger object to access the Simple Logging Facade for Java (SLF4J) facilities. The following code shows an example of the logger object.
logger.info("Parameters passed in: {} {} {}", param1, param2, param3);To set the log level for JavaScript scripts, add the following property to your project’s conf/logging.properties
file:
org.forgerock.openidm.script.javascript.JavaScript.levelThe level can be one of SEVERE (highest value), WARNING, INFO, CONFIG, FINE, FINER, or FINEST (lowest value). For example:
org.forgerock.openidm.script.javascript.JavaScript.level=WARNINGIn addition, JavaScript has a useful logging function named console.log(). This function provides an easy way to dump data to the IDM standard output (usually the same output as the OSGi console). The function works well with the JavaScript built-in function JSON.stringify and provides fine-grained details about any given object. For example, the following line will print a formatted JSON structure that represents the HTTP request details to STDOUT.
console.log(JSON.stringify(context.http, null, 4));|
These logging functions apply only to JavaScript scripts. To use the logging functions in Groovy scripts, the following lines must be added to the Groovy scripts: groovy |
The script engine supports the following log functions:
logger.debug(string message, object… params)
Logs a message at DEBUG level.
- Parameters
-
- message
-
string
The message format to log. Params replace
{}in your message. - params
-
object
Arguments to include in the message.
- Returns
-
A
nullvalue if successful. - Throws
-
An exception is thrown if the message could not be logged.
logger.error(string message, object… params)
Logs a message at ERROR level.
- Parameters
-
- message
-
string
The message format to log. Params replace
{}in your message. - params
-
object
Arguments to include in the message.
- Returns
-
A
nullvalue if successful. - Throws
-
An exception is thrown if the message could not be logged.
logger.info(string message, object… params)
Logs a message at INFO level.
- Parameters
-
- message
-
string
The message format to log. Params replace
{}in your message. - params
-
object
Arguments to include in the message.
- Returns
-
A
nullvalue if successful. - Throws
-
An exception is thrown if the message could not be logged.
logger.trace(string message, object… params)
Logs a message at TRACE level.
- Parameters
-
- message
-
string
The message format to log. Params replace
{}in your message. - params
-
object
Arguments to include in the message.
- Returns
-
A
nullvalue if successful. - Throws
-
An exception is thrown if the message could not be logged.
logger.warn(string message, object… params)
Logs a message at WARN level.
- Parameters
-
- message
-
string
The message format to log. Params replace
{}in your message. - params
-
object
Arguments to include in the message.
- Returns
-
A
nullvalue if successful. - Throws
-
An exception is thrown if the message could not be logged.