Architecture, availability, and disaster recovery
Advanced Identity Cloud is built on a highly available, globally distributed architecture that ensures your identity services remain operational even in the event of failures or disruptions. This architecture provides resilience, scalability, and performance for your identity management needs in the following ways:
-
Global services: Load balancers, configuration storage, and ESV storage are global services and remain available during the failure of a single region.
-
Redundancy and scaling: Workloads are deployed to clusters across multiple availability zones within a region to create redundancy. In the event of physical hardware failure within a particular zone, workloads are automatically redistributed to other zones. Ping Identity monitors your environments and appropriately scales each one to meet expected demands.
-
Availability and disaster recovery: Two deployment options are available to meet different availability and disaster recovery requirements:
-
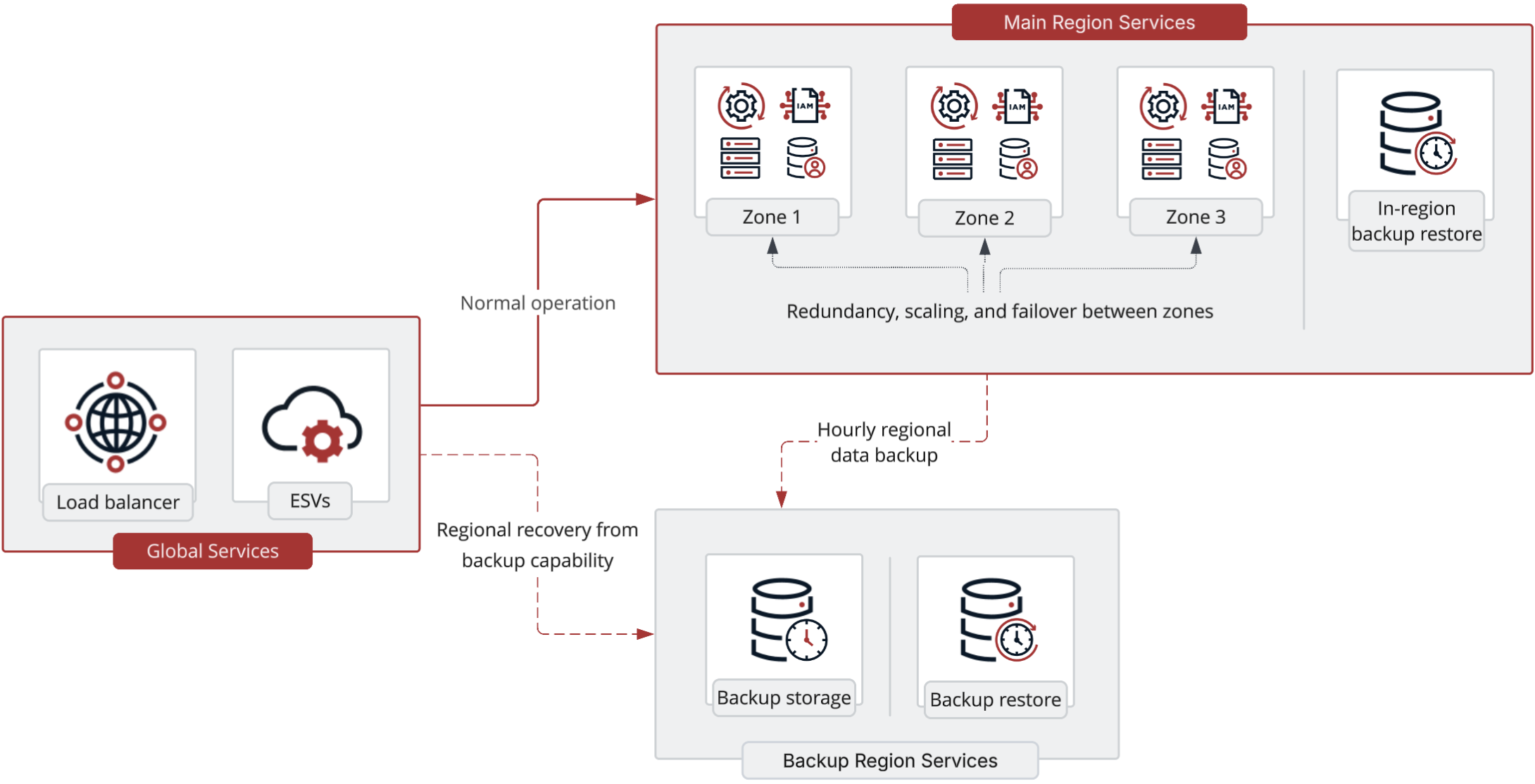
Single region (default): This deployment option hosts identity-related services in a single main region, with data backed up hourly to a separate backup region. It supports restoration to the main region or the backup region in the event of data corruption or regional failure.
-
Multi-region high availability (add-on capability): This deployment option hosts identity-related services across both a primary and a secondary region, with data replicated in near real-time. It allows for rapid failover to the secondary region in the event of a failure in the primary region, with a significantly better recovery time objective (RTO) and recovery point objective (RPO).
For a quick comparison of these deployment options, refer to Comparison of deployment options.
-
Deployment options
Single region
This deployment option is available in all environments and is the default option included with your Advanced Identity Cloud subscription.
A single-region deployment hosts identity-related services in a single main region, spread across three availability zones for resilience. Data is backed up hourly to a separate backup region. This supports three key recovery scenarios:
-
Restore from backup: In the event of data corruption, you can restore the datastore, including user identities and the identity schema, to any point within the retention period, which is 30 days for production environments. The available restore points are determined by the hourly backup schedule. An in-region restore typically takes under 1 hour, with an RPO of under 1 hour.
-
In-region disaster recovery: In the event of a significant service disruption or infrastructure failure within the main region, but where the region is still operational, service can be restored from backup in under 1 hour with an RPO of under 1 hour.
-
Backup region disaster recovery: In the event of a failure in the main region, and where the region is no longer operational, service can be restored in the backup region in under 4 hours with an RPO of under 1 hour.
Multi-region high availability
|
Advanced Identity Cloud add-on capability[2]
Contact your Ping Identity representative if you want to add this feature to your PingOne Advanced Identity Cloud subscription. Learn more in Add-on capabilities. |
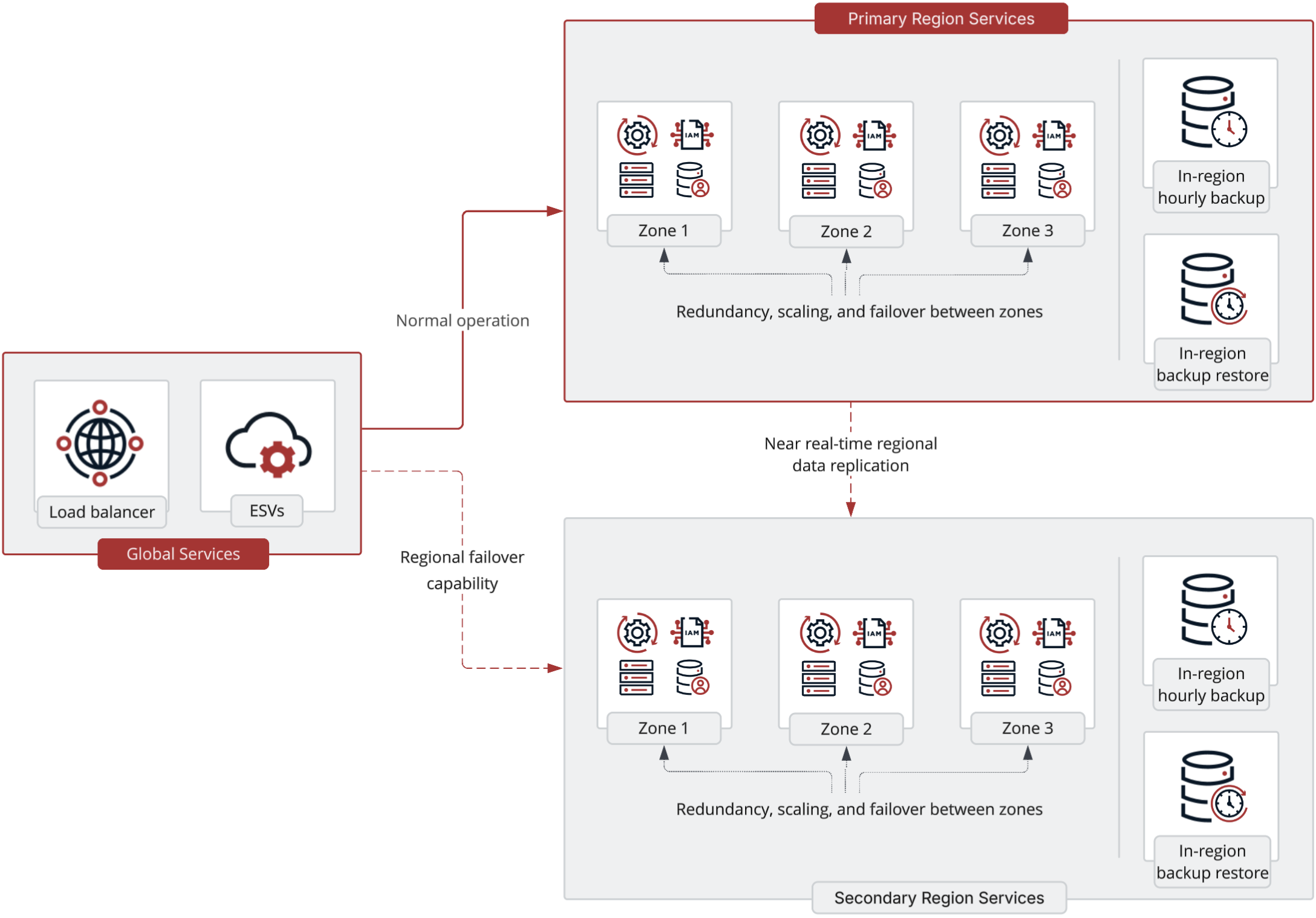
This deployment option is available in your staging and production environments only and is an add-on capability to your Advanced Identity Cloud subscription. It’s also dependent on the Outbound static IP addresses feature.
A multi-region deployment hosts identity-related services across both a primary and a secondary region, with data replicated between them in near real-time. This active-passive setup allows for a much faster response to failures. In the event of a failure in the primary region, service can be failed over to the secondary region in under 10 minutes with an RPO of near zero[1].
No additional configuration is required from you to support the multi-region deployment compared to the standard single-region deployment. Both regions are available using the same hostname and IP addresses for inbound and outbound traffic. However, an additional hostname is provided to let you monitor the failover services in the secondary region.
Both regions must be in the same geographic area (geo). For example, both in the United States or both in Europe. If there isn’t a second region in your geo, you can choose it from another geo, as long as it’s geographically nearby. For example, Sydney (in the Australia geo) and Jakarta (in the Asia geo).
Comparison of deployment options
| Feature | Single region | Multi-region high availability |
|---|---|---|
Default deployment option? |
Default |
Add-on capability |
Available in all environments? |
All environments |
Staging and production only |
SLA |
99.99% |
99.99% |
Load balancer |
Uses global load balancer to maintain availability during the failure of a single region. |
|
Configuration and ESV storage |
Configuration storage and ESV storage are global services and remain available during the failure of a single region. |
|
Identity, relationship, and token data storage |
Hosted in a single main region across three availability zones. |
Hosted in a primary region and a secondary region across three zones per region. |
Backup of disk snapshots |
Taken hourly in the main region and backed up to a backup region. |
Taken hourly in both regions and backed up to the same region. |
RCS endpoint configuration for staging and production environments |
3 endpoints in the main region |
3 endpoints in the primary region, 3 endpoints in the secondary region. Learn more in Configure a remote connector server. |
Replication |
N/A |
Identity, relationship, and token data are replicated between the primary and secondary regions in near real-time. |
Recovery mechanism for regional failure where the region is no longer operational |
In the event of the main region having a failure and no longer being operational, service is restored in the backup region. |
In the event of the primary region having a failure and no longer being operational, service is failed over to the secondary region. |
Production RTO for regional failure with service restored to backup or secondary region |
Under 4 hours |
Under 10 minutes[1] |
Production RPO for regional failure with service restored to backup or secondary region |
Under 1 hour |
Near zero[1] |
Release deferral |
If you opt in to release deferral, the release upgrade schedule is determined by the 7-day deferral period. Learn more in Upgrade scenario for a single-region deployment. |
If you opt in to release deferral, the release upgrade schedule is determined by both the 7-day deferral period and an additional multi-region delay period. Learn more in Upgrade scenario for a multi-region deployment. |
For a more specific breakdown of RTO and RPO targets for different recovery scenarios, refer to Recovery time objective (RTO) and recovery point objective (RPO).